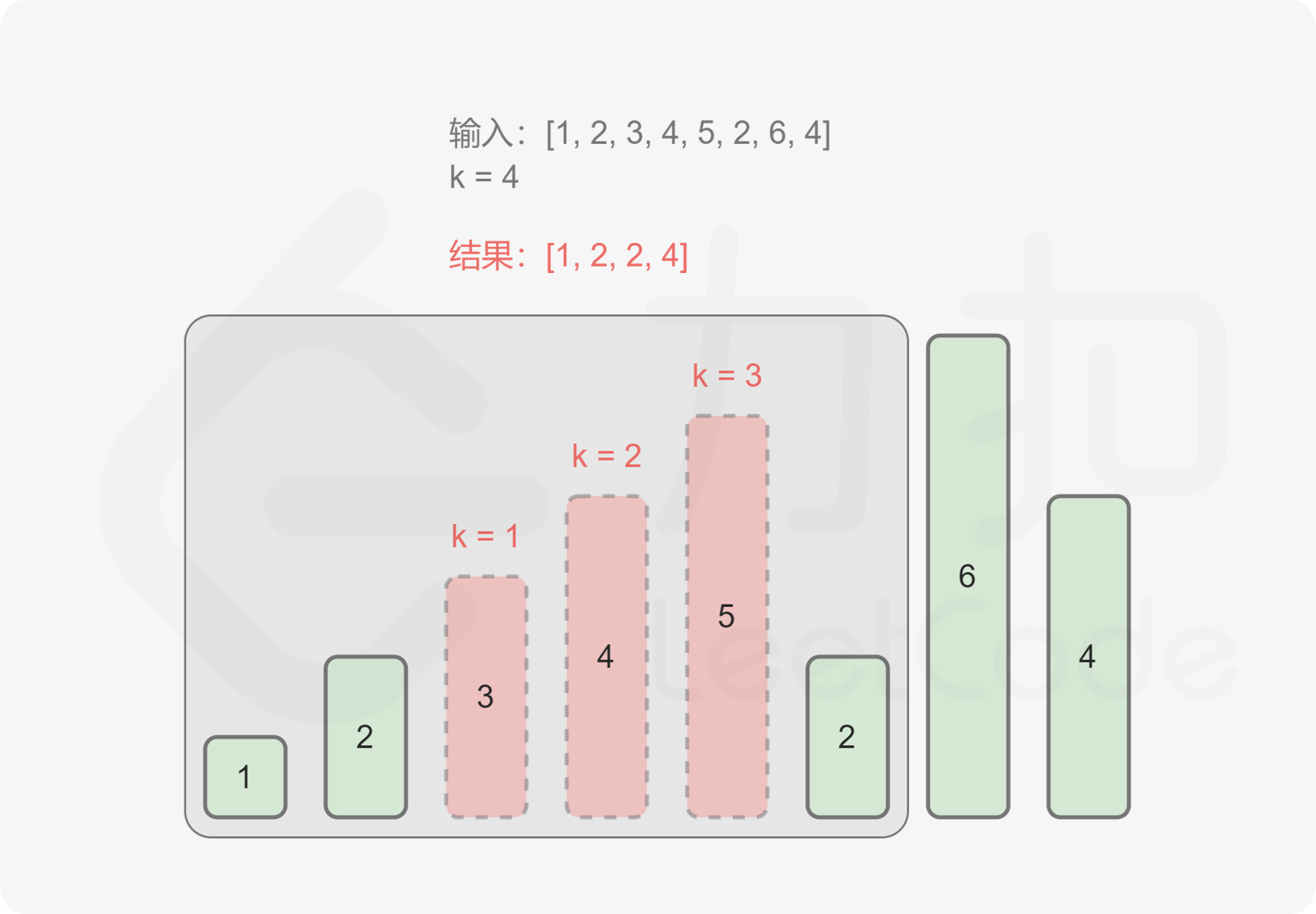
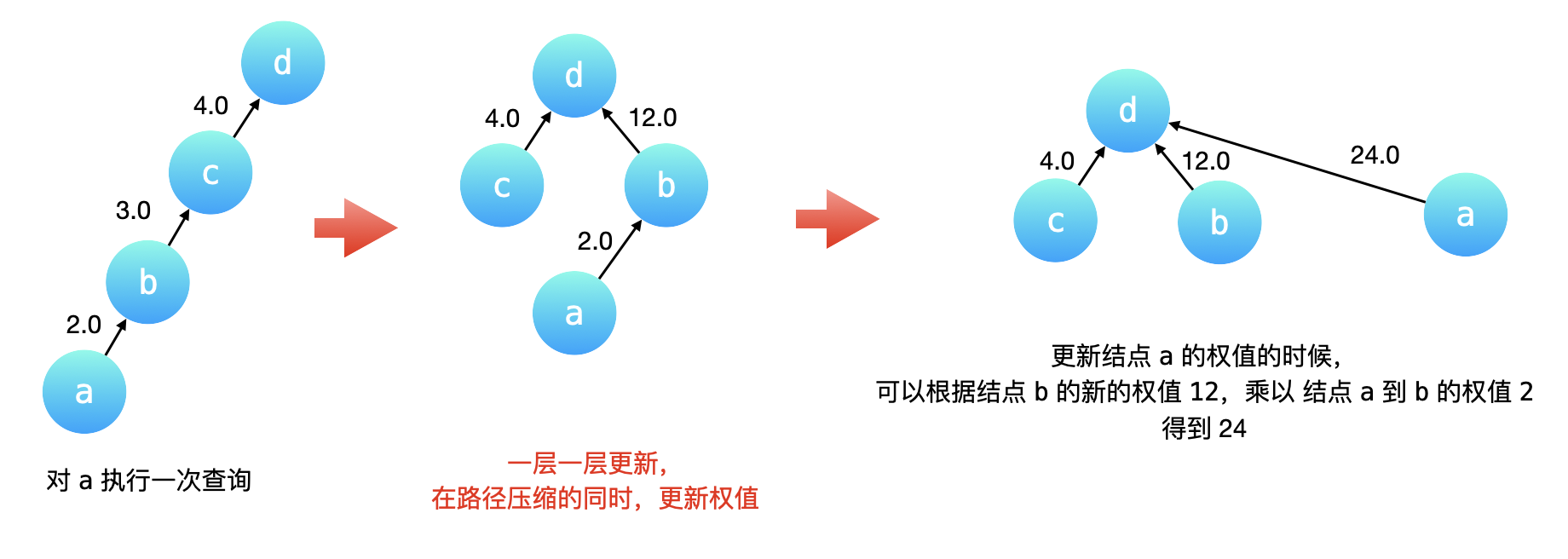
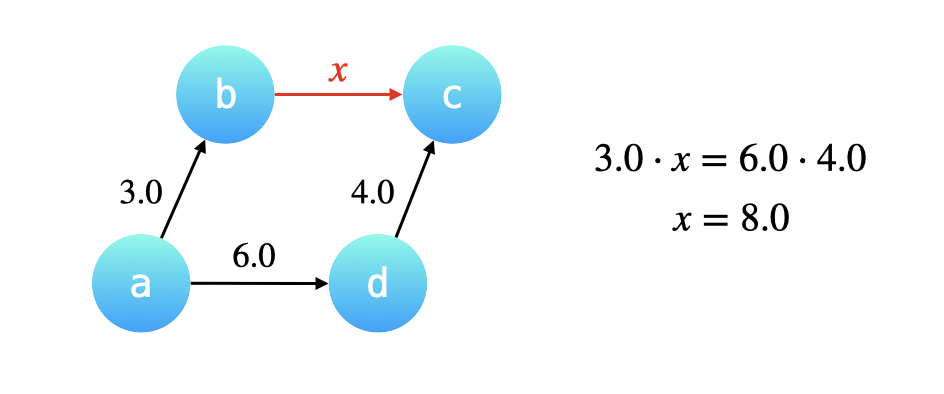
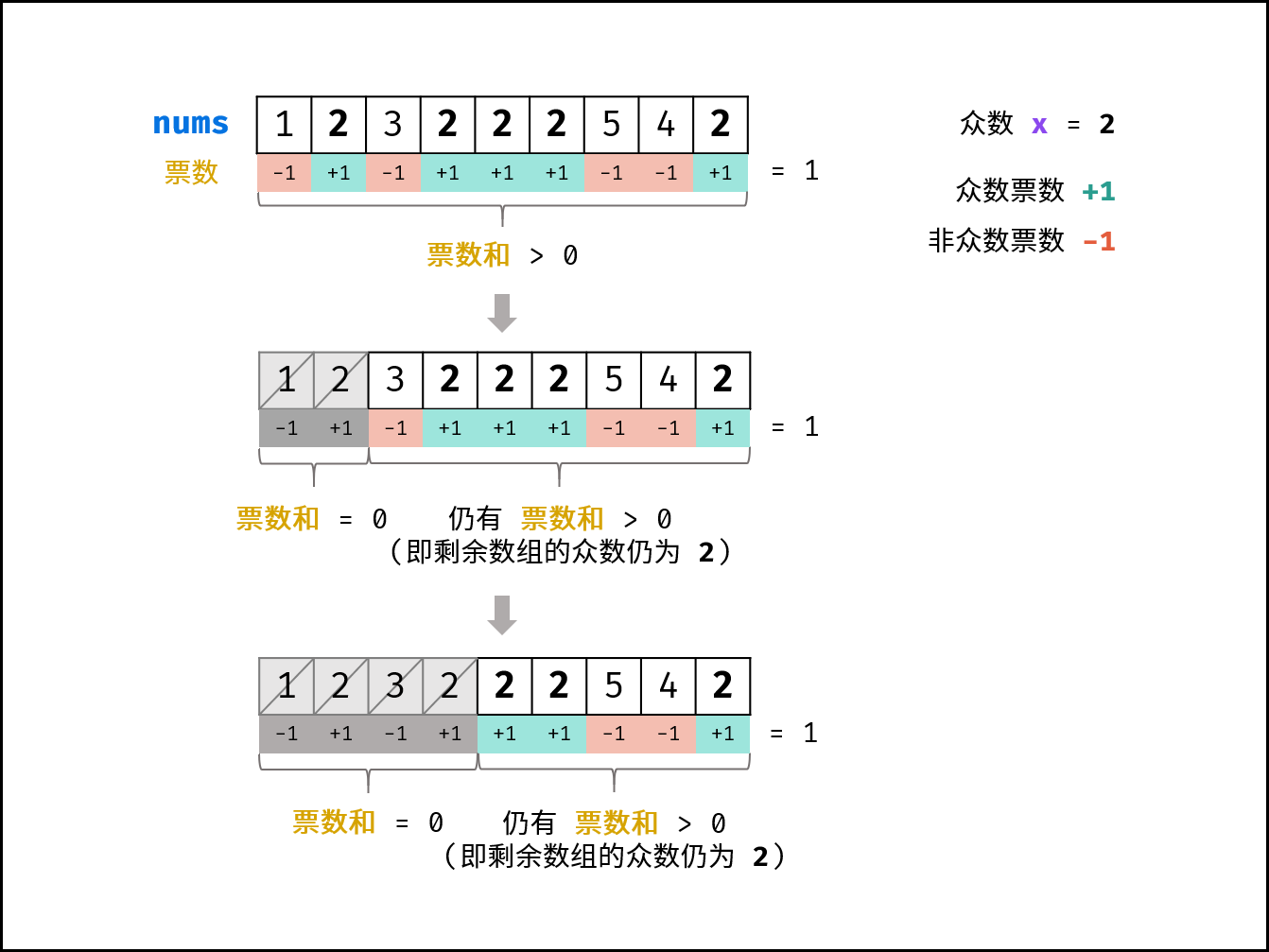
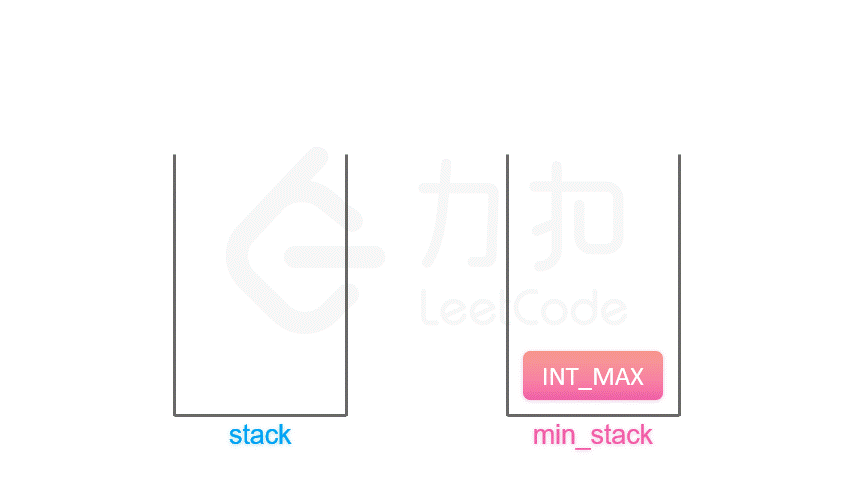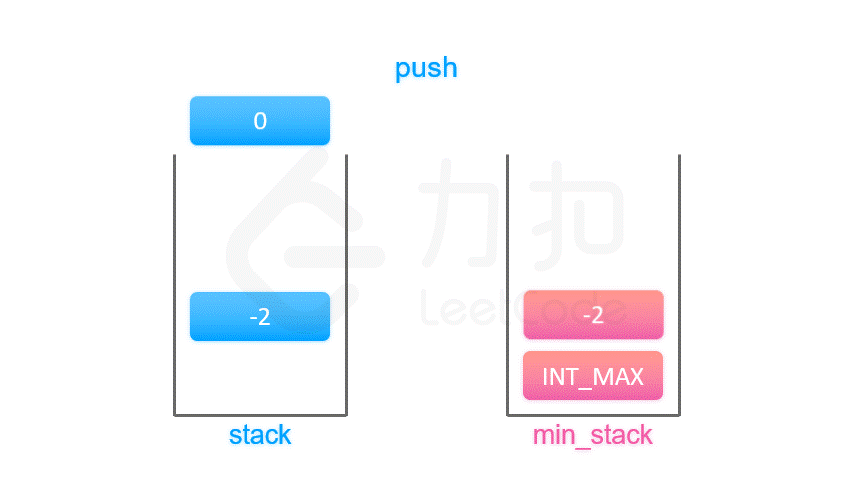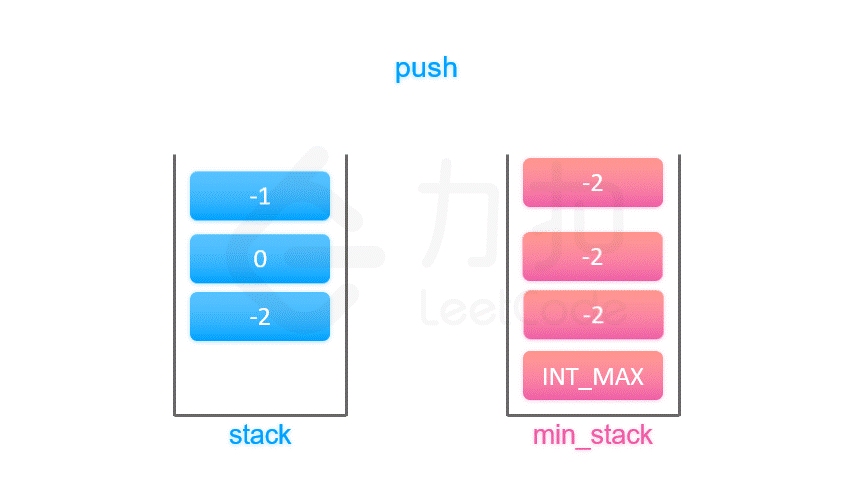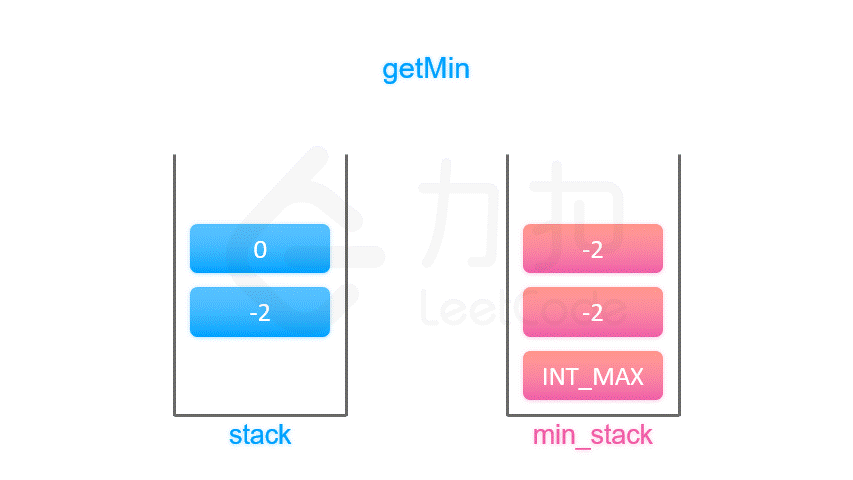
1️⃣在生成最低成汇编指令时,对volatile修饰的共享变量写操作增加Lock前缀指令,Lock 前缀的指令会引起 CPU 缓存写回内存; 2️⃣CPU 的缓存回写到内存会导致其他 CPU 缓存了该内存地址的数据无效; 3️⃣volatile 变量通过缓存一致性协议保证每个线程获得最新值; 4️⃣缓存一致性协议保证每个 CPU 通过嗅探在总线上传播的数据来检查自己缓存的值是不是修改; 5️⃣当 CPU 发现自己缓存行对应的内存地址被修改,会将当前 CPU 的缓存行设置成无效状态,重新从内存中把数据读到 CPU 缓存。
main 方法启动后,3 个线程会抢锁,但是 state 的初始值为 0,所以第一次执行 if 语句的内容只能是 线程 A,然后还在 for 循环之内,此时state = 1,只有 线程 B 才满足 1% 3 == 1,所以第二个执行的是 B,同理只有 线程 C 才满足 2% 3 == 2,所以第三个执行的是 C,执行完 ABC 之后,才去执行第二次 for 循环,所以要把 i++ 写在 for 循环里边,不能写成 for (int i = 0; i < times;i++) 这样。
We will used the doubly-linked list to build the LRU Dlink will have the prev pointer and the next pointer
the key :when we put new element into LRU we need to check whether we should remove the less used element, the key is used to use the method map.remove(redn.key) and update the hashmap
the value: use it to store the value;
the map : used to find the Dlinknode to choose update or delete the Dlinknode;
publicstaticvoidmain(String[] args)throws IOException { BufferedReaderbufferedReader=newBufferedReader(newInputStreamReader(System.in)); String[] str1 = bufferedReader.readLine().split(" "); n = Integer.parseInt(str1[0]); m = Integer.parseInt(str1[1]); k = Integer.parseInt(str1[2]);
for (inti=0; i < m; i ++) { String[] str2 = bufferedReader.readLine().split(" "); intx= Integer.parseInt(str2[0]); inty= Integer.parseInt(str2[1]); intz= Integer.parseInt(str2[2]); list[i] = newNode(x, y, z); }
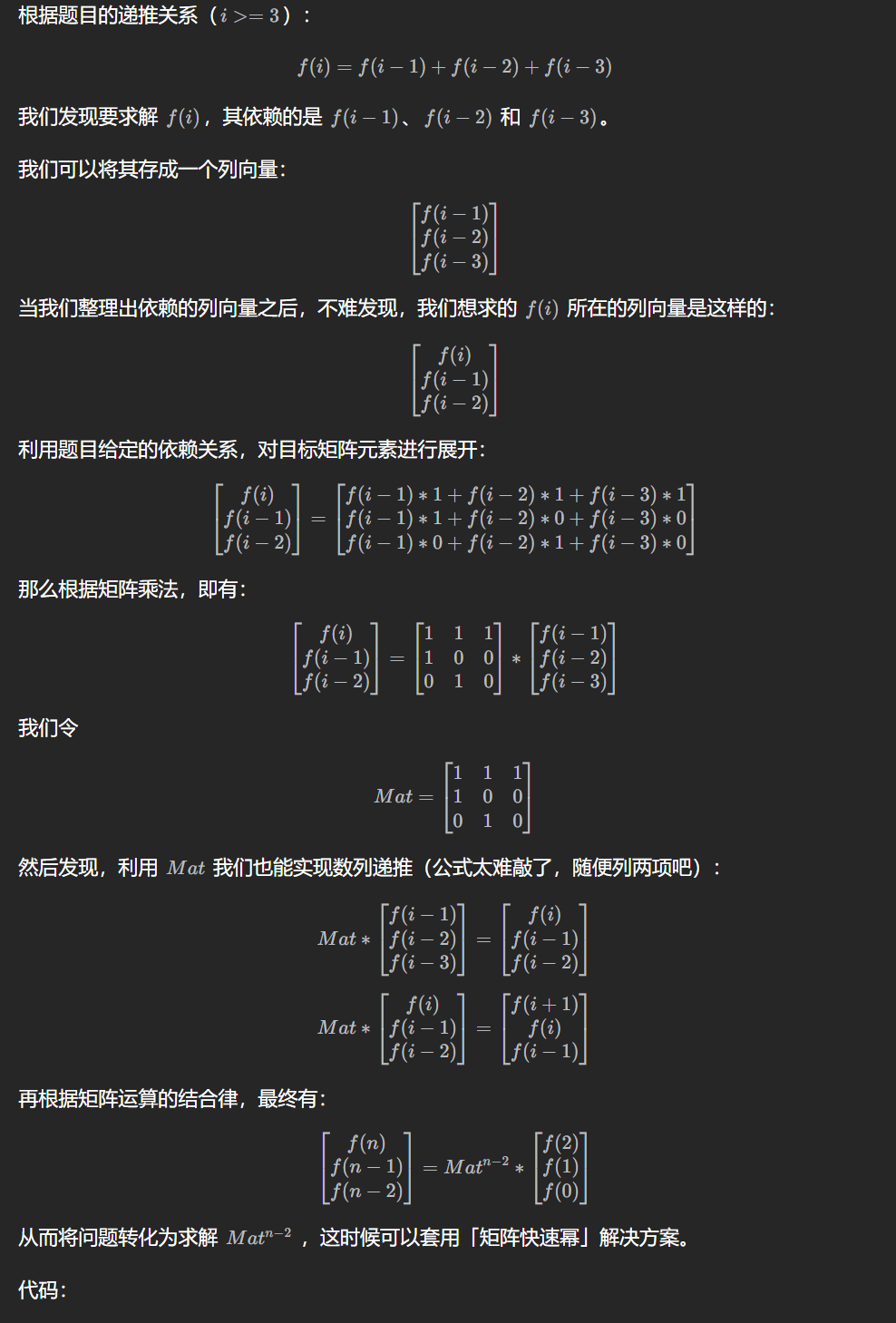
publicintnumberOfWays(String s, String t, long k) { intn= s.length(); intc= kmpSearch(s + s.substring(0, n - 1), t);//避免统计最后一个字母 long[][] m = { {c - 1, c}, {n - c, n - 1 - c}, }; m = pow(m, k); return s.equals(t) ? (int) m[0][0] : (int) m[0][1]; }
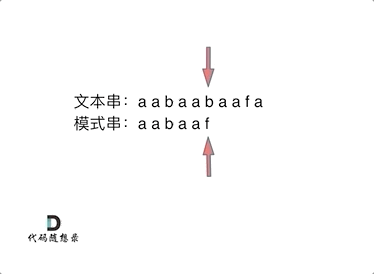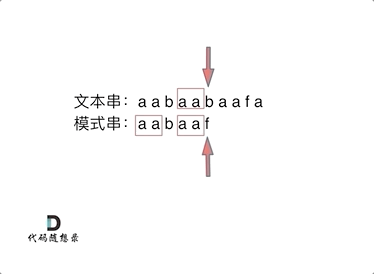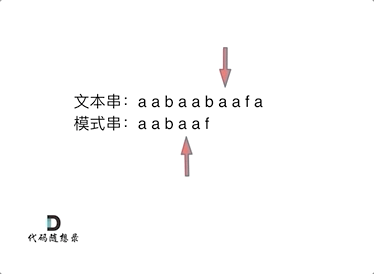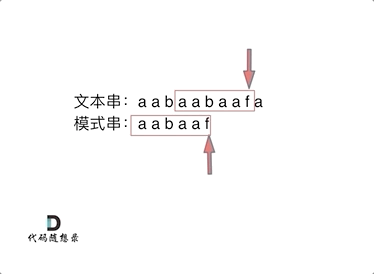
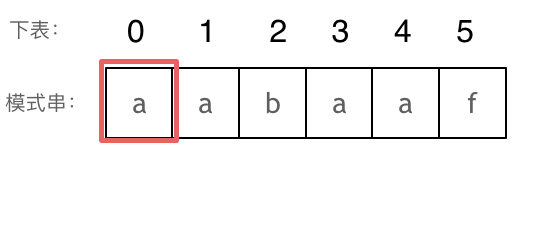
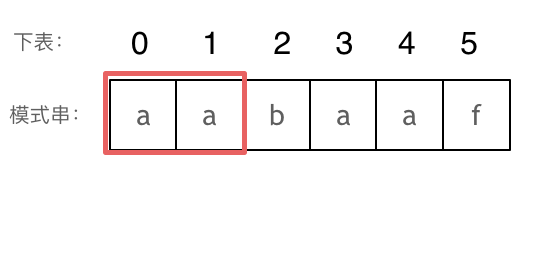
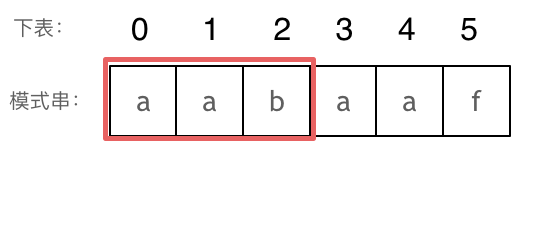
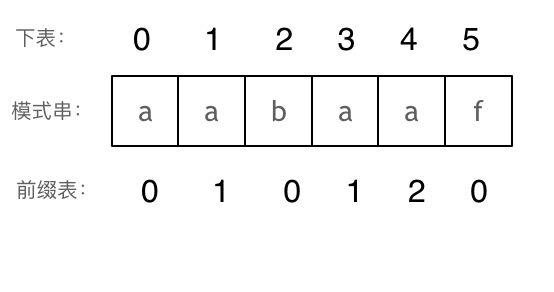
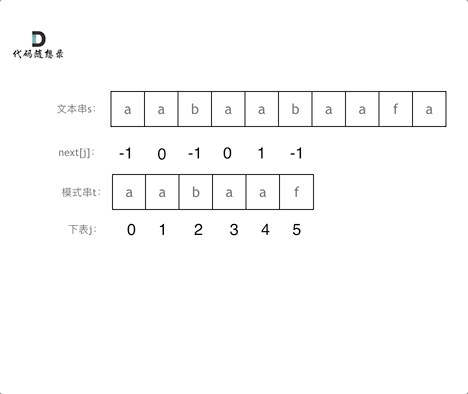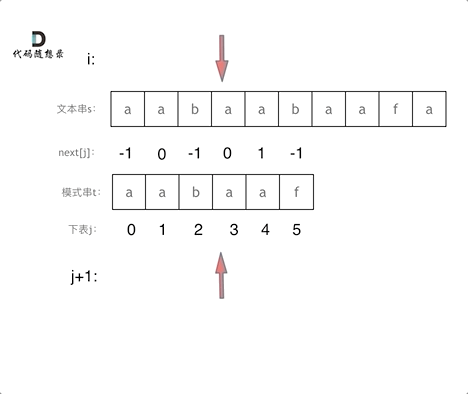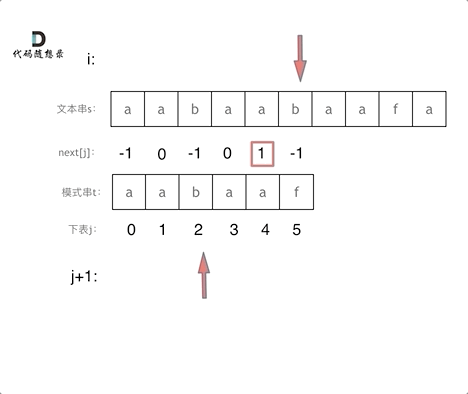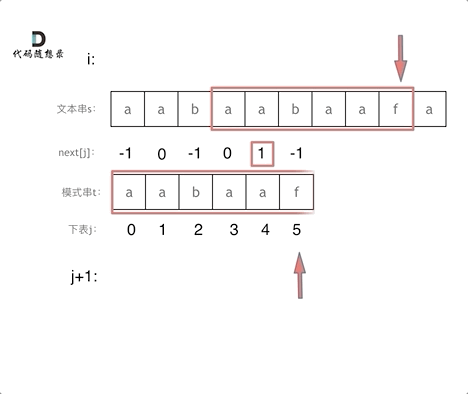
// KMP 模板 privateint[] calcMaxMatch(String s) { int[] match = newint[s.length()]; intc=0; for (inti=1; i < s.length(); i++) { charv= s.charAt(i); while (c > 0 && s.charAt(c) != v) { c = match[c - 1]; } if (s.charAt(c) == v) { c++; } match[i] = c; } return match; }
// KMP 模板 // 返回 text 中出现了多少次 pattern(允许 pattern 重叠) privateintkmpSearch(String text, String pattern) { int[] match = calcMaxMatch(pattern); intlenP= pattern.length(); intmatchCnt=0; intc=0; for (inti=0; i < text.length(); i++) { charv= text.charAt(i); while (c > 0 && pattern.charAt(c) != v) { c = match[c - 1]; } if (pattern.charAt(c) == v) { c++; } if (c == lenP) { matchCnt++; c = match[c - 1]; } } return matchCnt; }
privatestaticfinallongMOD= (long) 1e9 + 7;
// 矩阵乘法 privatelong[][] multiply(long[][] a, long[][] b) { long[][] c = newlong[2][2]; for (inti=0; i < 2; i++) { for (intj=0; j < 2; j++) { c[i][j] = (a[i][0] * b[0][j] + a[i][1] * b[1][j]) % MOD; } } return c; }
// 矩阵快速幂 privatelong[][] pow(long[][] a, long n) { long[][] res = {{1, 0}, {0, 1}}; for (; n > 0; n /= 2) {//二分法求幂 if (n % 2 > 0) { res = multiply(res, a); } a = multiply(a, a); } return res; }
private List<Integer>[] g; privateint[] ans, size; publicint[] sumOfDistancesInTree(int n, int[][] edges) { g = newArrayList[n]; // g[x] 表示 x 的所有邻居 Arrays.setAll(g, e -> newArrayList<>()); for (int [] e : edges) { intx= e[0], y = e[1]; g[x].add(y); g[y].add(x); } ans = newint[n]; size = newint[n]; dfs(0, -1, 0); // 0 没有父节点 reroot(0, -1); // 0 没有父节点 return ans; }
privatevoiddfs(int x, int fa, int depth) { ans[0] += depth; // depth 为 0 到 x 的距离 size[x] = 1; for (int y : g[x]) { // 遍历 x 的邻居 y if (y != fa) { // 避免访问父节点 dfs(y, x, depth + 1); // x 是 y 的父节点 size[x] += size[y]; // 累加 x 的儿子 y 的子树大小 } } }
privatevoidreroot(int x, int fa) { for (int y : g[x]) { // 遍历 x 的邻居 y if (y != fa) { // 避免访问父节点 ans[y] = ans[x] + g.length - 2 * size[y]; reroot(y, x); // x 是 y 的父节点 } } }
Queue<Integer>min=newPriorityQueue<>(); Queue<Integer>max=newPriorityQueue<>(); publicMedianFinder() { min = newPriorityQueue<Integer>((a, b) -> (b - a)); max = newPriorityQueue<Integer>((a, b) -> (a - b)); }
/* //使用 Lambda 表达式改写 Comparator Comparator<Integer> comparator = (i1, i2) -> { int scoreComparison = scores.get(i1).compareTo(scores.get(i2)); if (scoreComparison != 0) { return scoreComparison; } // If scores are the same, compare names in reversed order return names.get(i2).compareTo(names.get(i1)); }; //重写 compare 方法 Comparator<Integer> comparator = new Comparator<Integer>() { @Override public int compare(Integer i1, Integer i2) { int scoreComparison = scores.get(i1).compareTo(scores.get(i2)); if (scoreComparison != 0) { return scoreComparison; } // If scores are the same, compare names in reversed order return names.get(i2).compareTo(names.get(i1)); } }; */
Queue<Integer> minHeap = newPriorityQueue<>(comparator); Queue<Integer> maxHeap = newPriorityQueue<>(comparator.reversed()); Comparator<Integer> comparator = newComparator<Integer>() { @Override publicintcompare(Integer i1, Integer i2) { intscoreComparison= scores.get(i1).compareTo(scores.get(i2)); if (scoreComparison != 0) { return scoreComparison; } // If scores are the same, compare names in reversed order return names.get(i2).compareTo(names.get(i1)); } };
public List<String> findWords(char[][] board, String[] words) { Trietrie=newTrie(); for (String word : words) { trie.insert(word); }
Set<String> ans = newHashSet<String>(); for (inti=0; i < board.length; ++i) { for (intj=0; j < board[0].length; ++j) { dfs(board, trie, i, j, ans); } }
returnnewArrayList<String>(ans); }
publicvoiddfs(char[][] board, Trie now, int i1, int j1, Set<String> ans) { if (!now.children.containsKey(board[i1][j1])) { return; } charch= board[i1][j1]; Trienxt= now.children.get(ch); if (!"".equals(nxt.word)) { ans.add(nxt.word); nxt.word = ""; }
publicbooleancarPooling(int[][] trips, int capacity) { int[] d = newint[1001]; for (int[] t : trips) { intnum= t[0], from = t[1], to = t[2]; d[from] += num; d[to] -= num; } ints=0; for (int v : d) { s += v; if (s > capacity) { returnfalse; } } returntrue; }
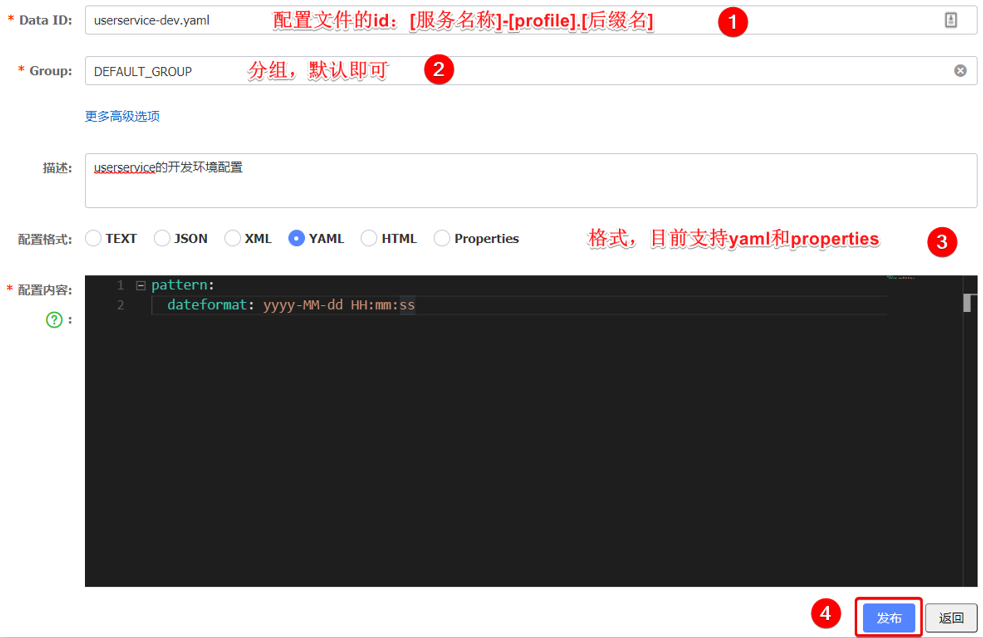
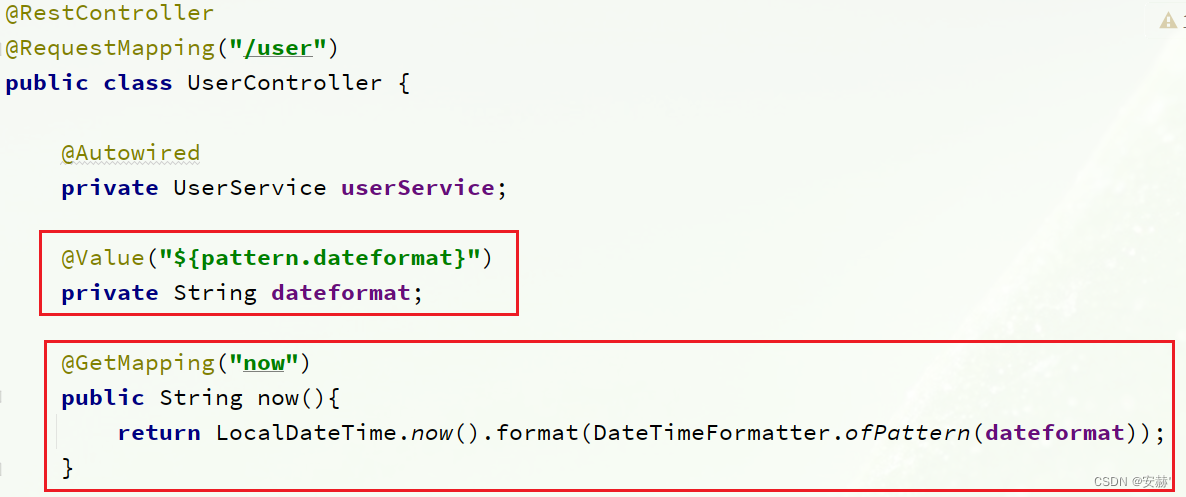
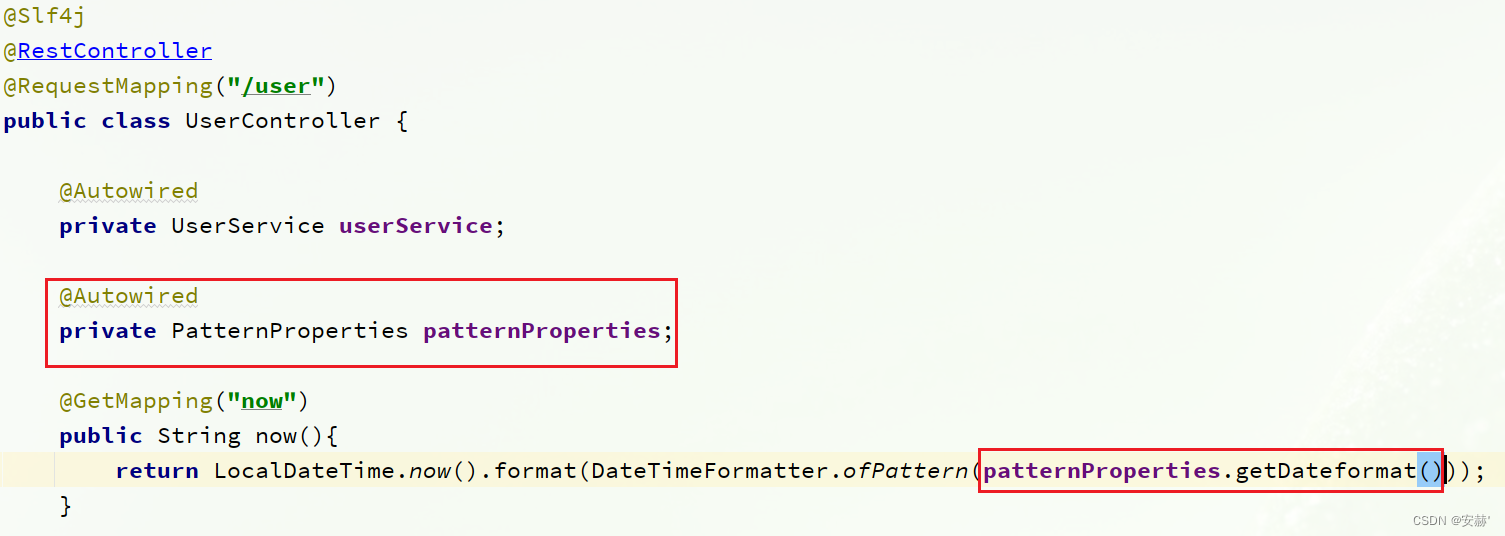
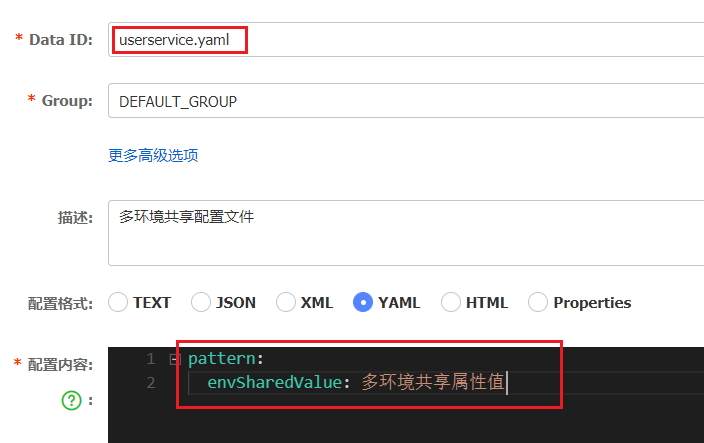
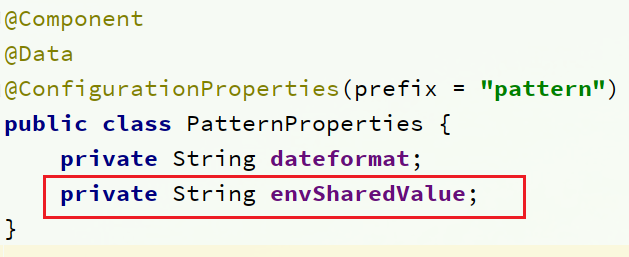
s p r i n g . a p p l i c a t i o n . n a m e − {spring.application.name}-spring.application.name−{spring.profiles.active}.${spring.cloud.nacos.config.file-extension}作为文件id,来读取配置。
publicintkthSmallest(int[][] matrix, int k) { intn= matrix.length; intleft= matrix[0][0]; intright= matrix[n - 1][n - 1]; while (left < right) { intmid= left + ((right - left) >> 1); if (check(matrix, mid, k, n)) { right = mid; } else { left = mid + 1; } } return left; }
publicbooleancheck(int[][] matrix, int mid, int k, int n) { inti= n - 1; intj=0; intnum=0; while (i >= 0 && j < n) { if (matrix[i][j] <= mid) { num += i + 1; j++; } else { i--; } } return num >= k; }
intl=0; // l 标记从前往后找到第一个出现降序的下标,nums[l] > nums[l + 1] while (l + 1 < n && nums[l] <= nums[l + 1]) { l++; }
// 若l == n - 1, 说明 nums 为升序序列 if (l == n - 1) { return0; }
intr= n - 1; // r 标记从后往前找到第一个出现升序的下标,nums[r] < nums[r - 1] while (r - 1 >= 0 && nums[r] >= nums[r - 1]) { r--; }
/* 在子区间 [l, r] 中找到最小值 min 和最大值 max*/ intmin= nums[l]; intmax= nums[r]; for (inti= l, j = r; i <= r && j >= l; i++, j--) { min = min < nums[i] ? min : nums[i]; max = max > nums[j] ? max : nums[j]; }
/* 从 l 开始向前查找 min 在 nums 中的最终位置 l */ while (l - 1 >= 0 && nums[l - 1] > min) { l--; } /* 从 r 开始向后查找 max 在 nums 中的最终位置 r*/ while (r + 1 < n && nums[r + 1] < max) { r++; } /* 确定无序子数组的最小值和最大值的最终位置后,[l, r] 中的元素就是原数组 nums 待排序的子数组*/ return r - l + 1; }
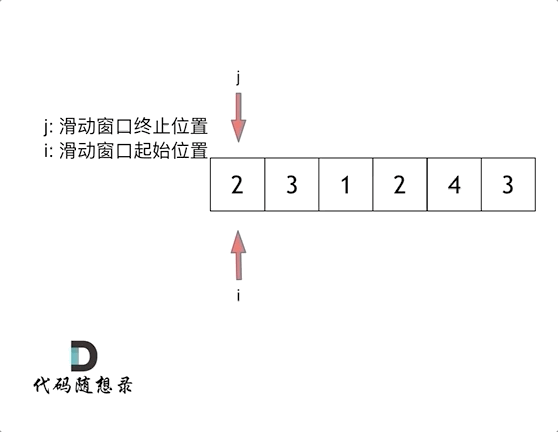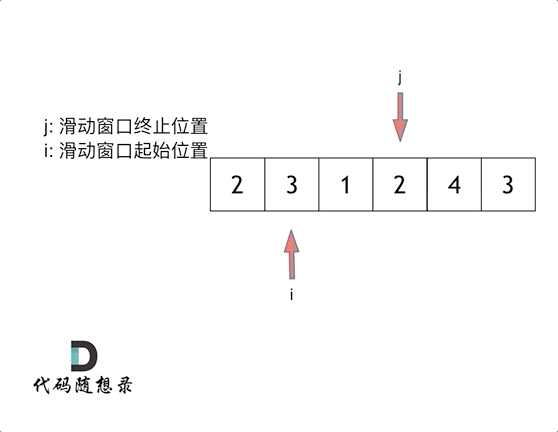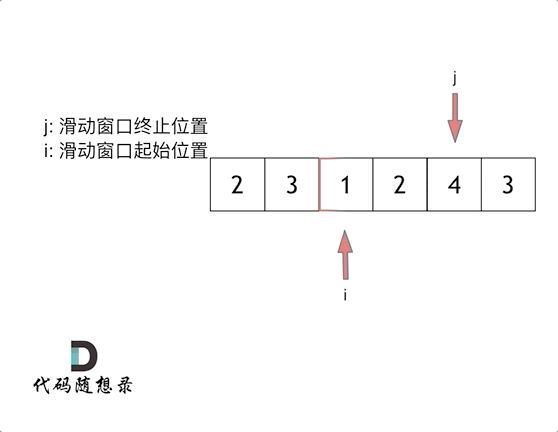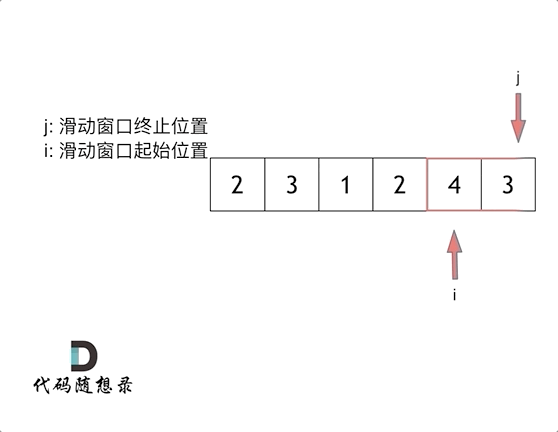
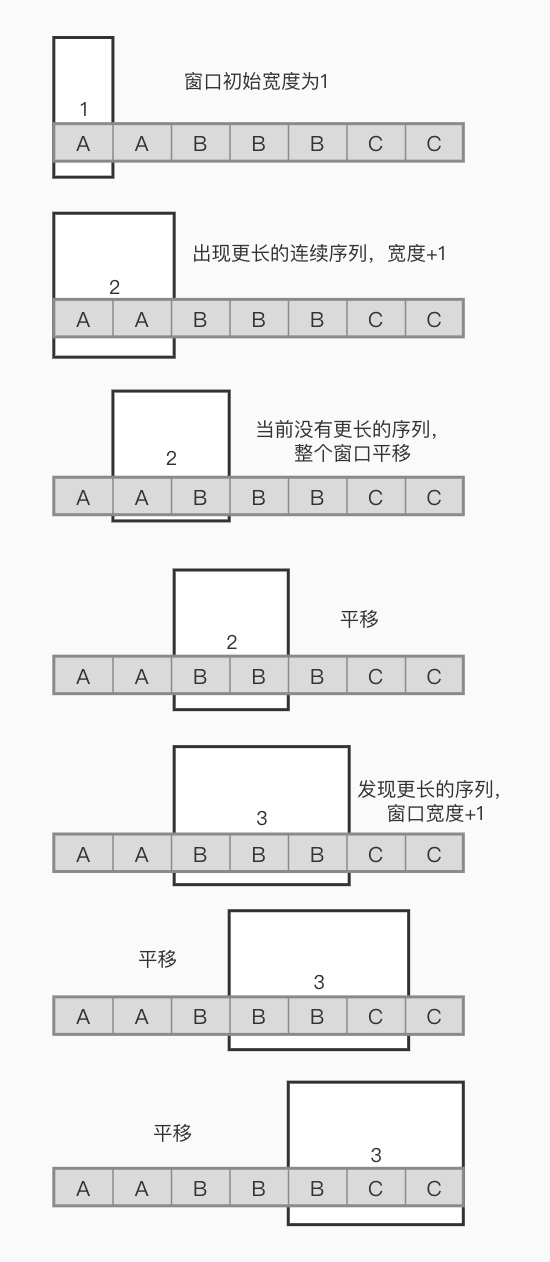
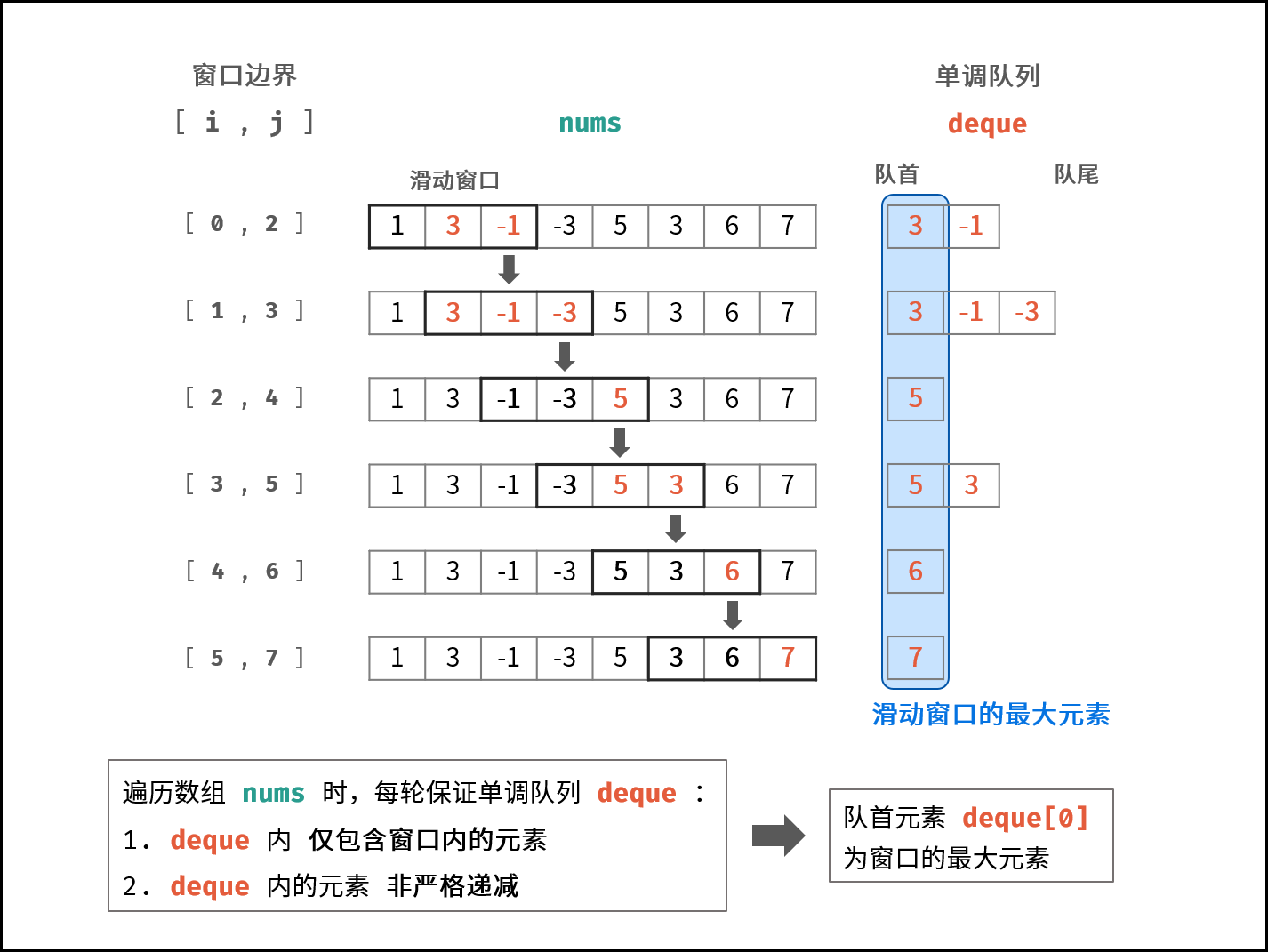
5、滑动窗口
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17
intminSubArrayLen(int s, vector<int>& nums){ int result = INT32_MAX; int sum = 0; // 滑动窗口数值之和 int i = 0; // 滑动窗口起始位置 int subLength = 0; // 滑动窗口的长度 for (int j = 0; j < nums.size(); j++) { sum += nums[j]; // 注意这里使用while,每次更新 i(起始位置),并不断比较子序列是否符合条件 while (sum >= s) { subLength = (j - i + 1); // 取子序列的长度 result = result < subLength ? result : subLength; sum -= nums[i++]; // 这里体现出滑动窗口的精髓之处,不断变更i(子序列的起始位置) } } // 如果result没有被赋值的话,就返回0,说明没有符合条件的子序列 return result == INT32_MAX ? 0 : result; }
注意需要统计次数时或者不求最大值时建议使用hashmap配合这样滑动窗口可以包含自身
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18
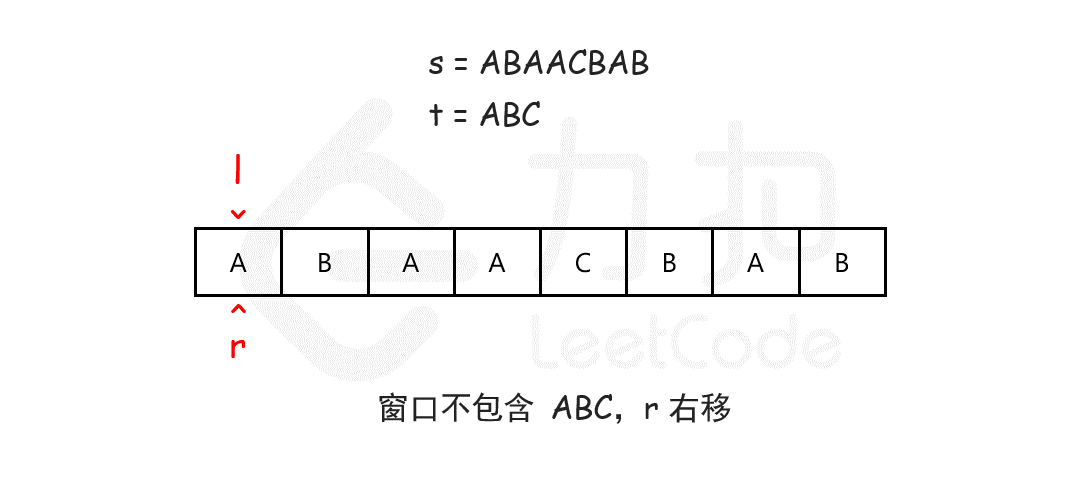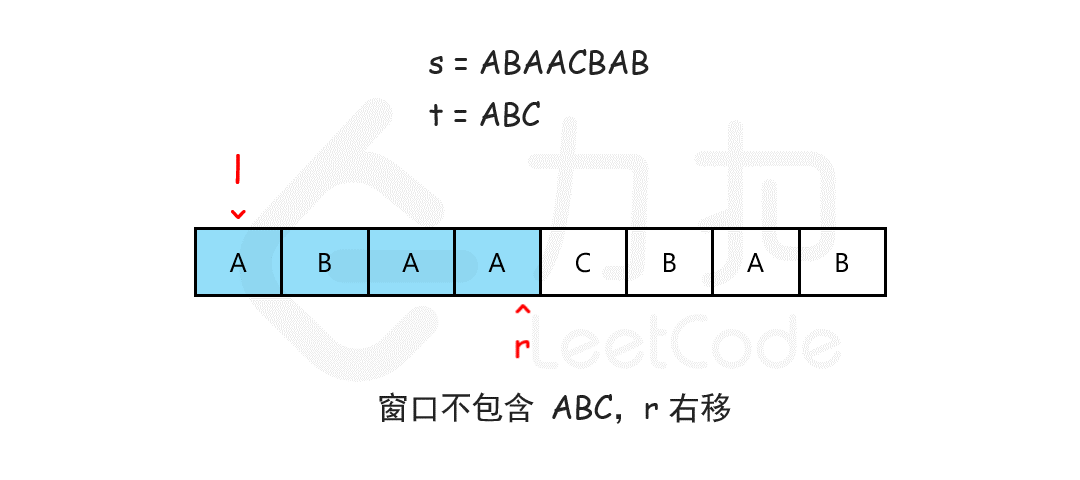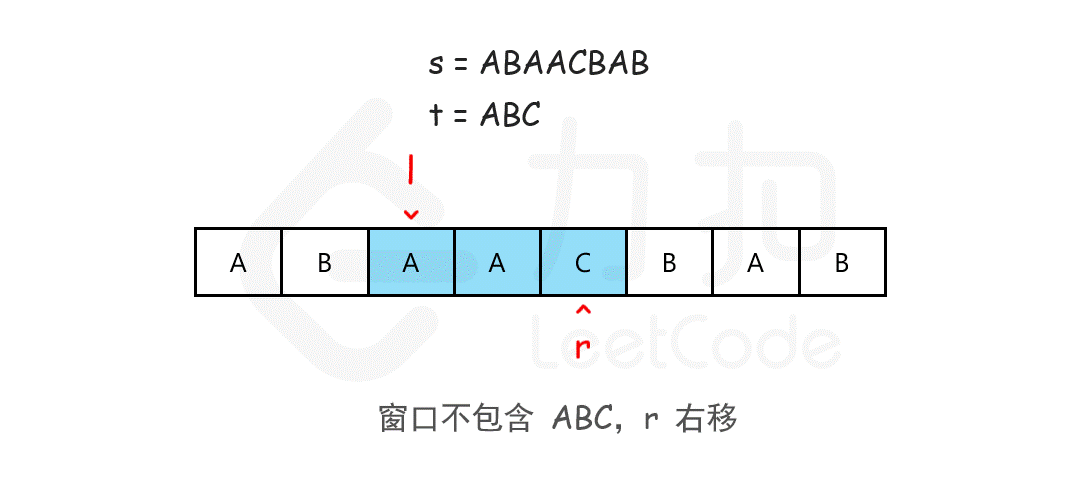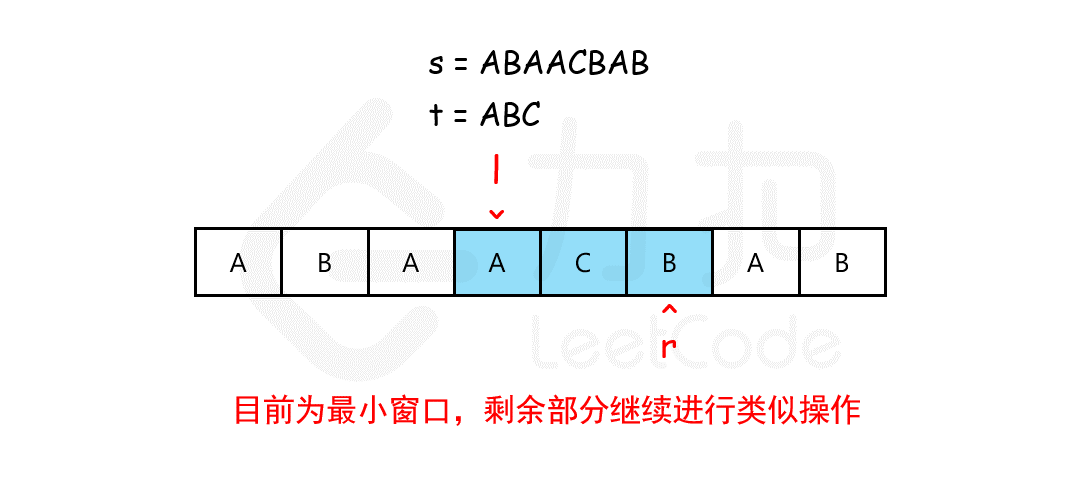
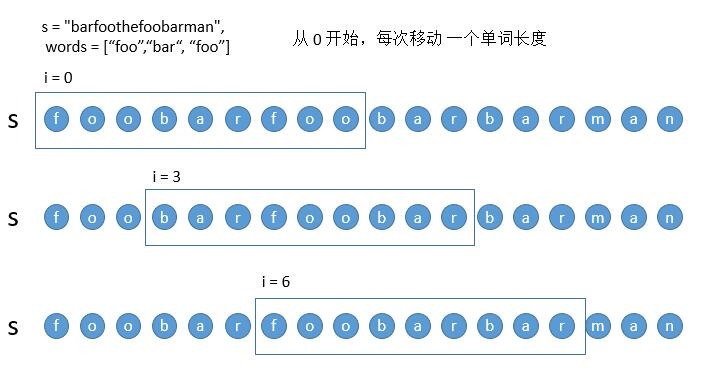
//76. 最小覆盖子串 https://leetcode.cn/problems/minimum-window-substring/description/ //这里面i就是r j就是l通过i右移先包含整个t字符然后再j右移删除无效字符 使用length 判断是否已经将t的字符全部匹配 public String minWindow(String s, String t) { char[] sc = s.toCharArray();char[] tc = t.toCharArray(); int [] hash=newint[128]; for (char ch : tc) hash[ch]--; Stringres=""; int length=0; for (inti=0,j=0; i < sc.length; i++) { hash[sc[i]]++; if(hash[sc[i]]<=0)length++; while (length == tc.length && hash[sc[j]] > 0) hash[sc[j++]]--; if(length==tc.length) if(res.equals("")||res.length()>i-j+1) res=s.substring(j,i+1);` } return res; }
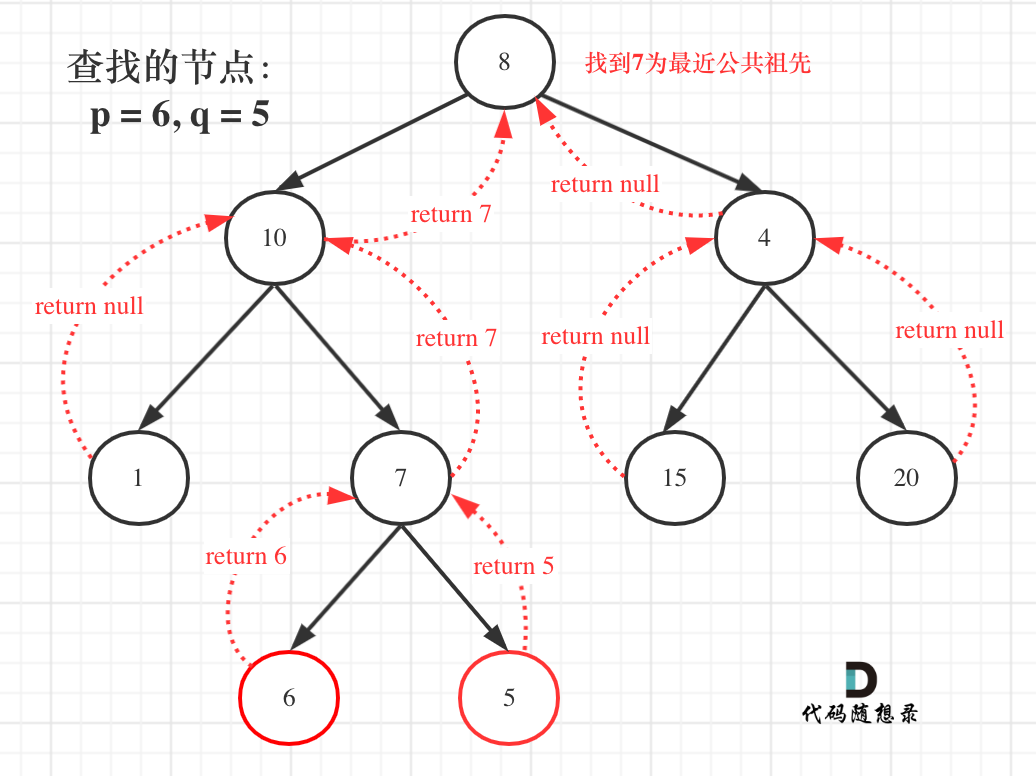
public ListNode getIntersectionNode(ListNode headA, ListNode headB) { ListNodeA= headA, B = headB; while (A != B) { A = A != null ? A.next : headB; B = B != null ? B.next : headA; } return A; }
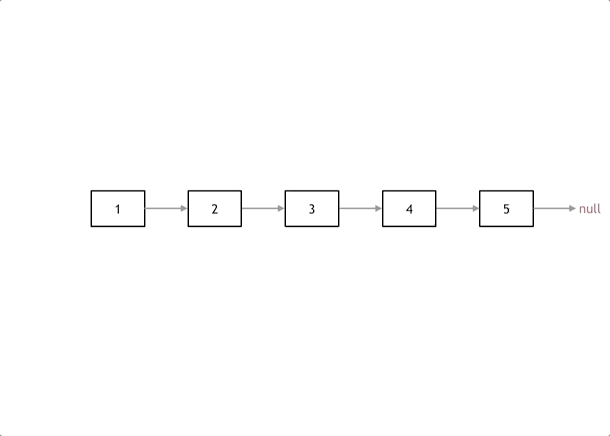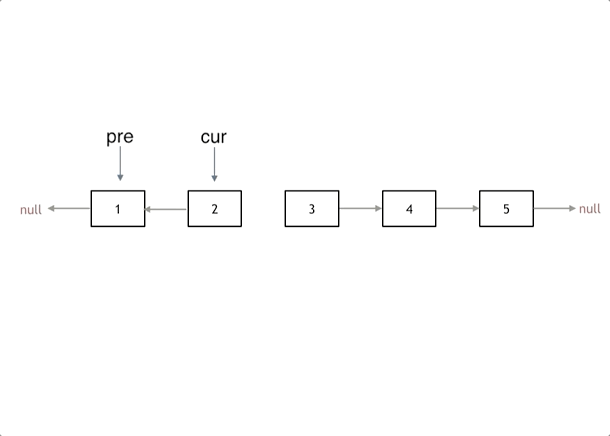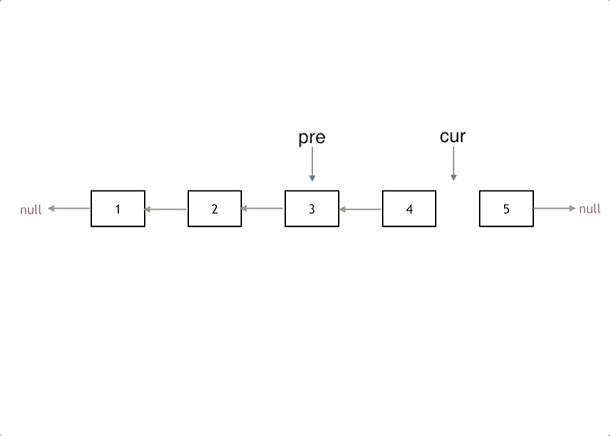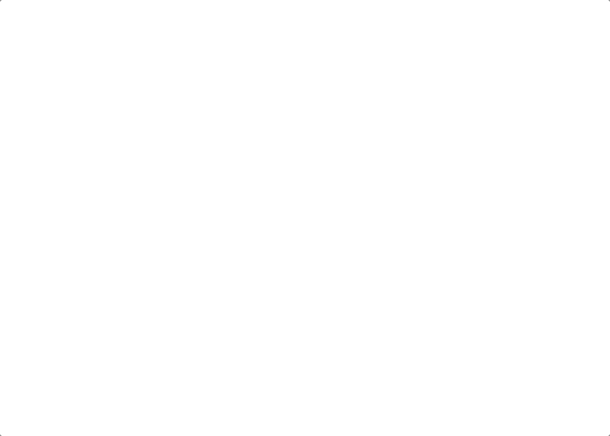
public ListNode reverseBetween(ListNode head, int left, int right) { ListNodedummy=newListNode(0, head), p0 = dummy; for (inti=0; i < left - 1; ++i) p0 = p0.next; ListNodepre=null, cur = p0.next; for (inti=0; i < right - left + 1; ++i) { ListNodenxt= cur.next; cur.next = pre; // 每次循环只修改一个 next,方便大家理解 pre = cur; cur = nxt; } p0.next.next = cur; p0.next = pre; return dummy.next; }
// Iterating entries using a For Each loop for (Map.Entry<Integer, Integer> entry : map.entrySet()) { System.out.println("Key = " + entry.getKey() + ", Value = " + entry.getValue()); } } }
publicintnumberOfWays(String s, String t, long k) { intn= s.length(); intc= kmpSearch(s + s.substring(0, n - 1), t);//避免统计最后一个字母 long[][] m = { {c - 1, c}, {n - c, n - 1 - c}, }; m = pow(m, k); return s.equals(t) ? (int) m[0][0] : (int) m[0][1]; }
// KMP 模板 privateint[] calcMaxMatch(String s) { int[] match = newint[s.length()]; intc=0; for (inti=1; i < s.length(); i++) { charv= s.charAt(i); while (c > 0 && s.charAt(c) != v) { c = match[c - 1]; } if (s.charAt(c) == v) { c++; } match[i] = c; } return match; }
// KMP 模板 // 返回 text 中出现了多少次 pattern(允许 pattern 重叠) privateintkmpSearch(String text, String pattern) { int[] match = calcMaxMatch(pattern); intlenP= pattern.length(); intmatchCnt=0; intc=0; for (inti=0; i < text.length(); i++) { charv= text.charAt(i); while (c > 0 && pattern.charAt(c) != v) { c = match[c - 1]; } if (pattern.charAt(c) == v) { c++; } if (c == lenP) { matchCnt++; c = match[c - 1]; } } return matchCnt; }
privatestaticfinallongMOD= (long) 1e9 + 7;
// 矩阵乘法 privatelong[][] multiply(long[][] a, long[][] b) { long[][] c = newlong[2][2]; for (inti=0; i < 2; i++) { for (intj=0; j < 2; j++) { c[i][j] = (a[i][0] * b[0][j] + a[i][1] * b[1][j]) % MOD; } } return c; }
// 矩阵快速幂 privatelong[][] pow(long[][] a, long n) { long[][] res = {{1, 0}, {0, 1}}; for (; n > 0; n /= 2) {//二分法求幂 if (n % 2 > 0) { res = multiply(res, a); } a = multiply(a, a); } return res; }
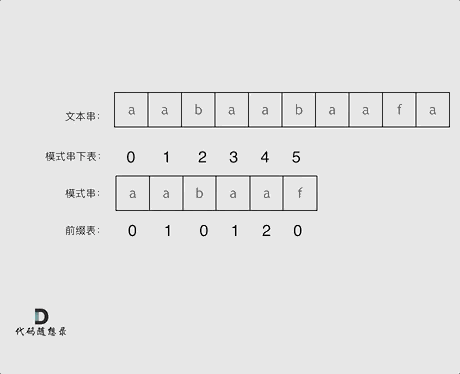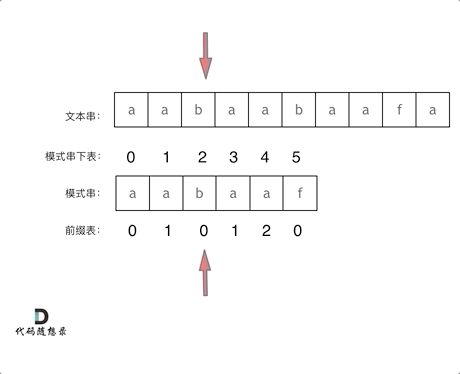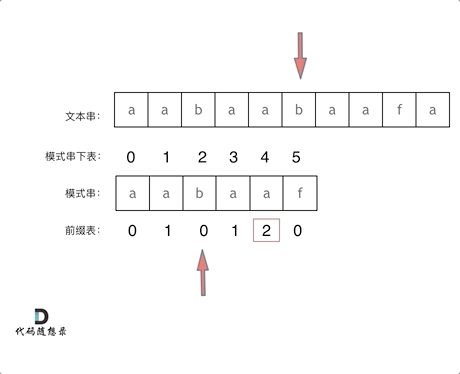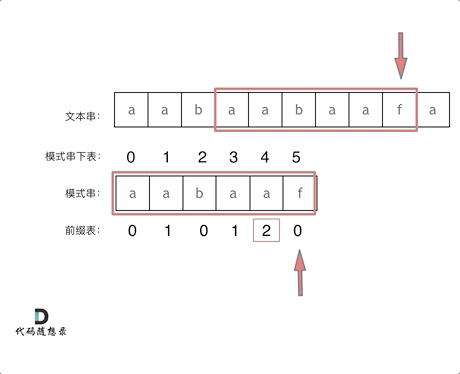
4.Z 函数(扩展 KMP)
对于个长度为 n 的字符串s。定义函数 **z[i]**表示 s 和 **s[i,n-1]**(即以 s[i]开头的后缀)的最长公共前缀(LCP)的长度。z被称为 s的 Z 函数。特别地,z[0] = 0
publicintminimumTimeToInitialState(String S, int k) { char[] s = S.toCharArray(); intn= s.length; int[] z = newint[n]; intl=0, r = 0; for (inti=1; i < n; i++) { if (i <= r) { z[i] = Math.min(z[i - l], r - i + 1); } while (i + z[i] < n && s[z[i]] == s[i + z[i]]) { l = i; r = i + z[i]; z[i]++; } if (i % k == 0 && z[i] >= n - i) { return i / k; } } return (n - 1) / k + 1; }
// 295. 数据流的中位数 https://leetcode.cn/problems/find-median-from-data-stream/?envType=study-plan-v2&envId=top-100-liked publicMedianFinder() { min = newPriorityQueue<Integer>((a, b) -> (b - a)); max = newPriorityQueue<Integer>((a, b) -> (a - b)); }
int[][] dirs = {{1, 0}, {-1, 0}, {0, 1}, {0, -1}}; //循环测试每个字母开头判断是否存在单词 public List<String> findWords(char[][] board, String[] words) { Trie2trie=newTrie2(); for (String word : words) { trie.insert(word); }
Set<String> ans = newHashSet<String>(); for (inti=0; i < board.length; ++i) { for (intj=0; j < board[0].length; ++j) { dfs(board, trie, i, j, ans); } }
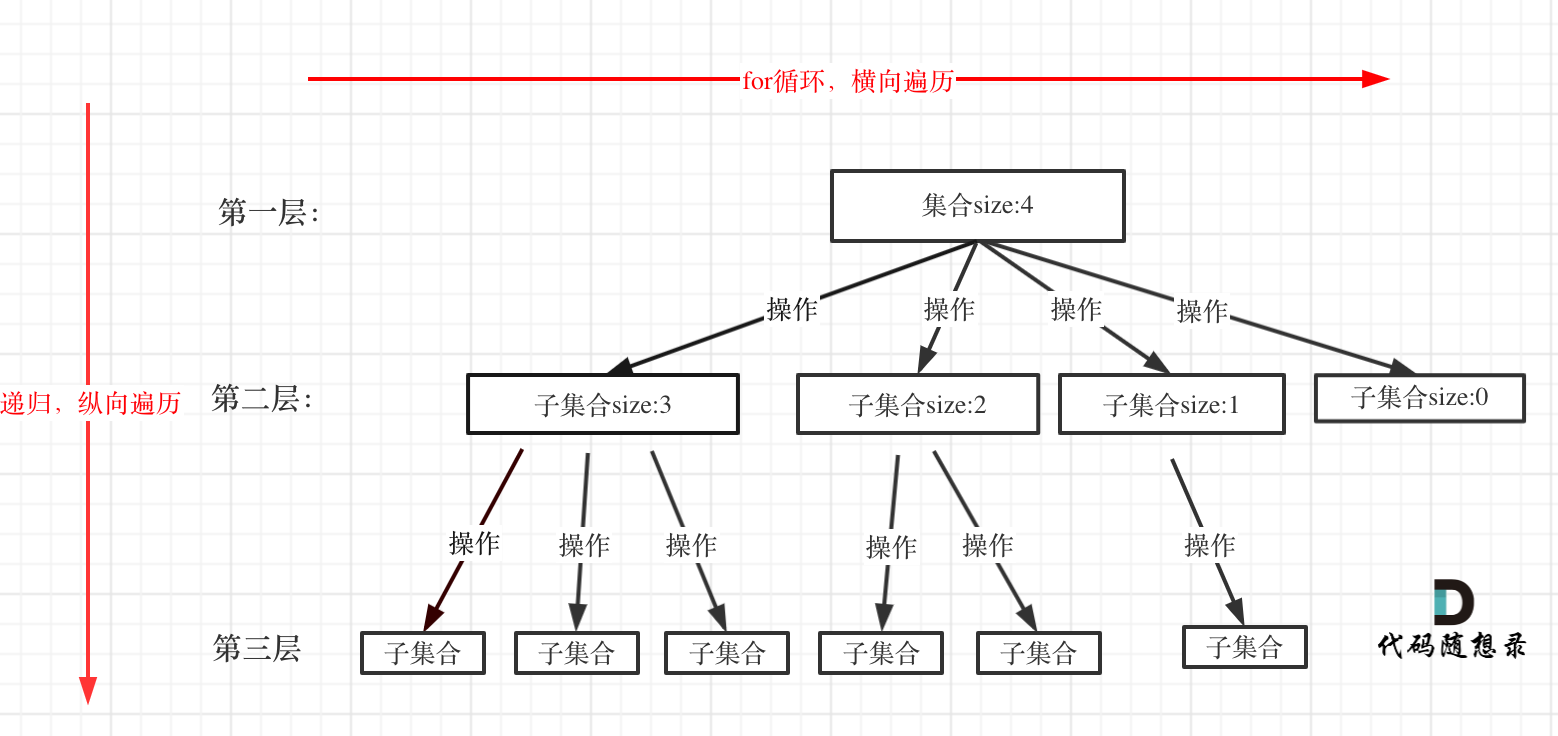
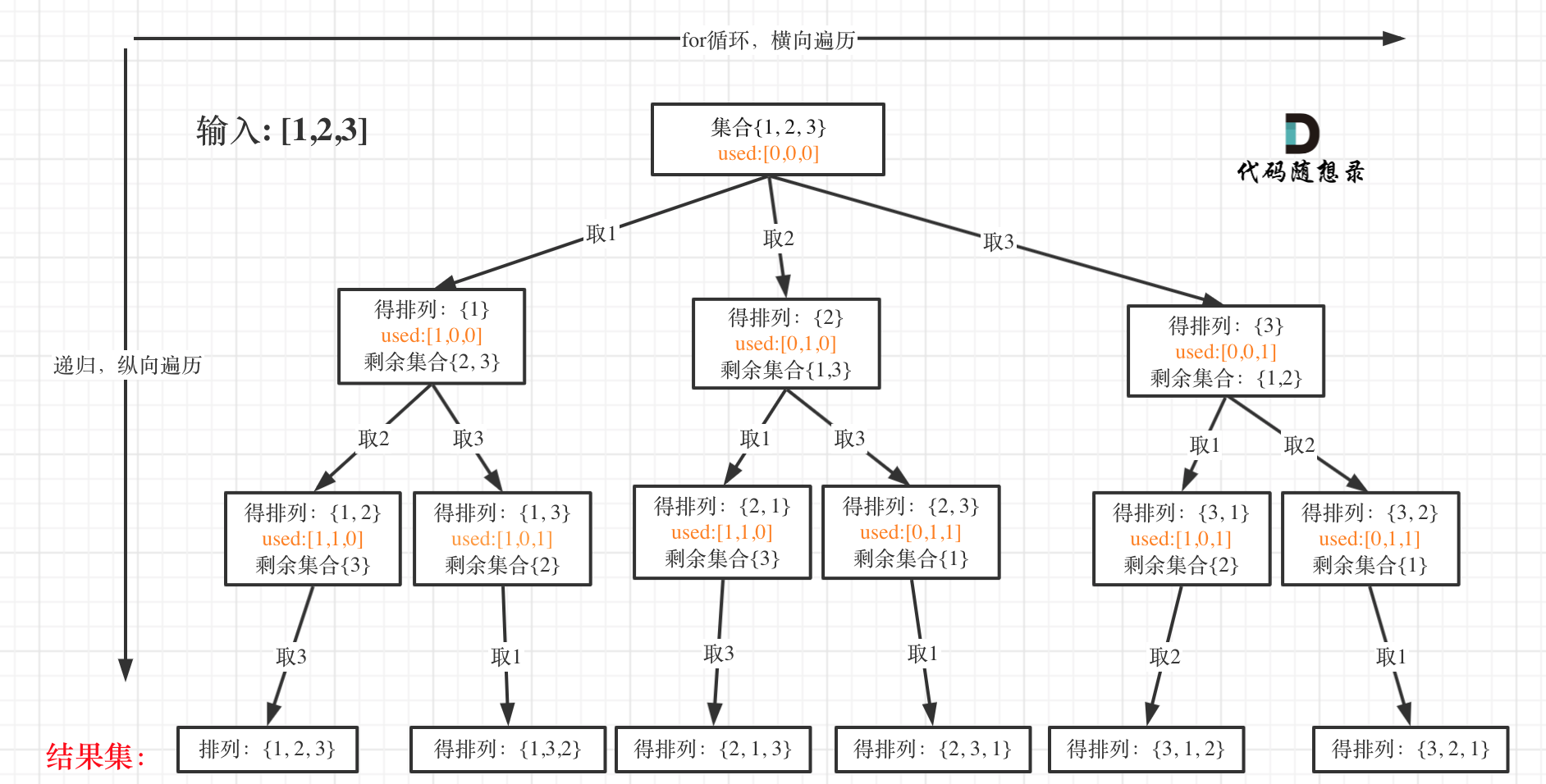
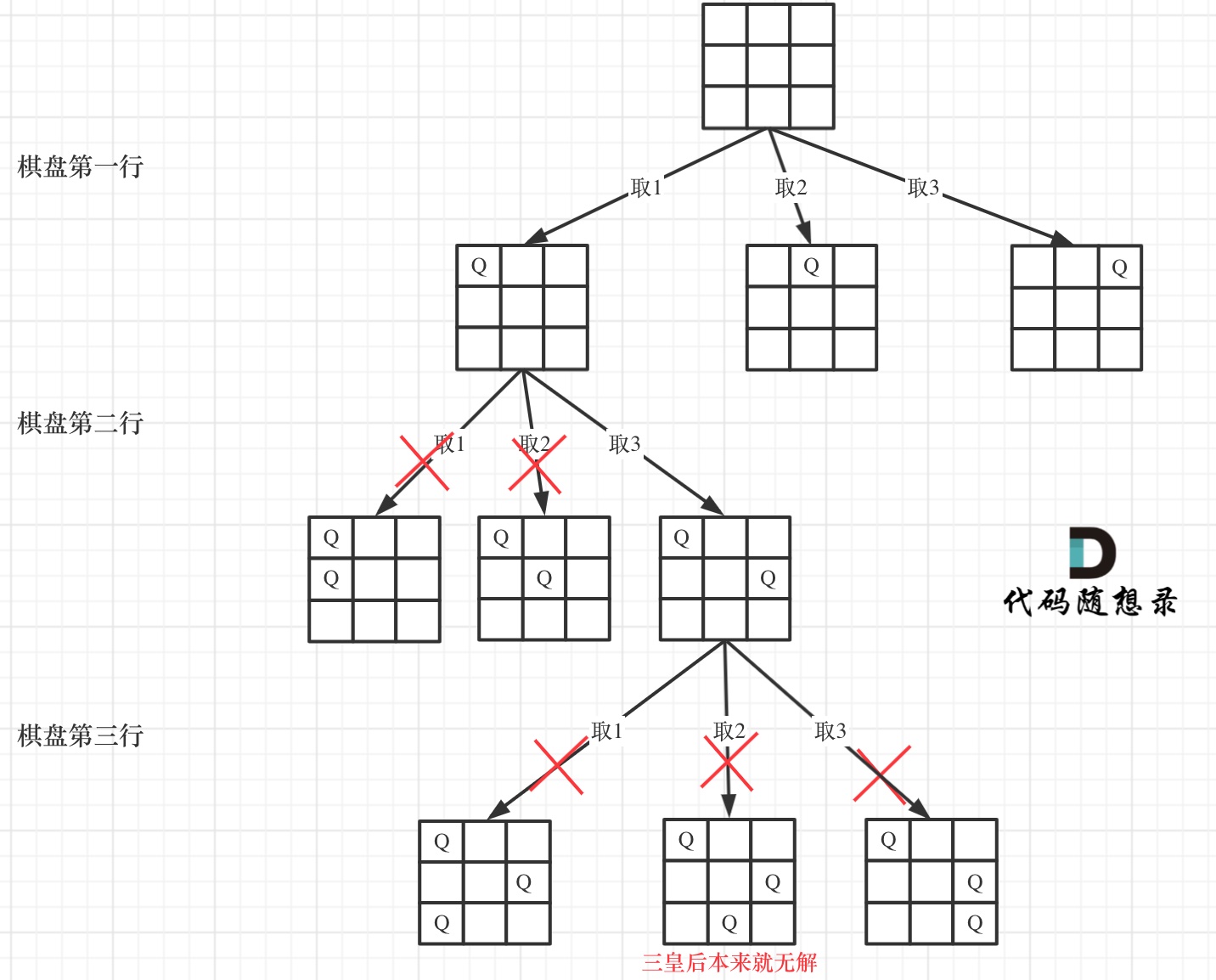
for (选择:本层集合中元素(树中节点孩子的数量就是集合的大小)) { 处理节点; backtracking(路径,选择列表); // 递归 回溯,撤销处理结果 }
分析完过程,回溯算法模板框架如下:
1 2 3 4 5 6 7 8 9 10 11 12
voidbacktracking(参数) { if (终止条件) { 存放结果; return; }
for (选择:本层集合中元素(树中节点孩子的数量就是集合的大小)) { 处理节点; backtracking(路径,选择列表); // 递归 回溯,撤销处理结果 } }
这份模板很重要,后面做回溯法的题目都靠它了!
回溯法解决的问题
回溯法,一般可以解决如下几种问题:
组合问题:N个数里面按一定规则找出k个数的集合
1 2 3 4 5 6 7 8 9 10 11 12
privatevoidcombineHelper(int n, int k, int startIndex){ //终止条件 if (path.size() == k){ result.add(newArrayList<>(path)); return; } for (inti= startIndex; i <= n - (k - path.size()) + 1; i++){ path.add(i); combineHelper(n, k, i + 1); path.removeLast(); } }
切割问题:一个字符串按一定规则有几种切割方式
1 2 3 4 5 6 7 8 9 10 11 12
for (inti= startIndex; i < s.length(); i++) { //如果是回文子串,则记录 if (isPalindrome(s, startIndex, i)) { Stringstr= s.substring(startIndex, i + 1); deque.addLast(str); } else { continue; } //起始位置后移,保证不重复 backTracking(s, i + 1); deque.removeLast(); }
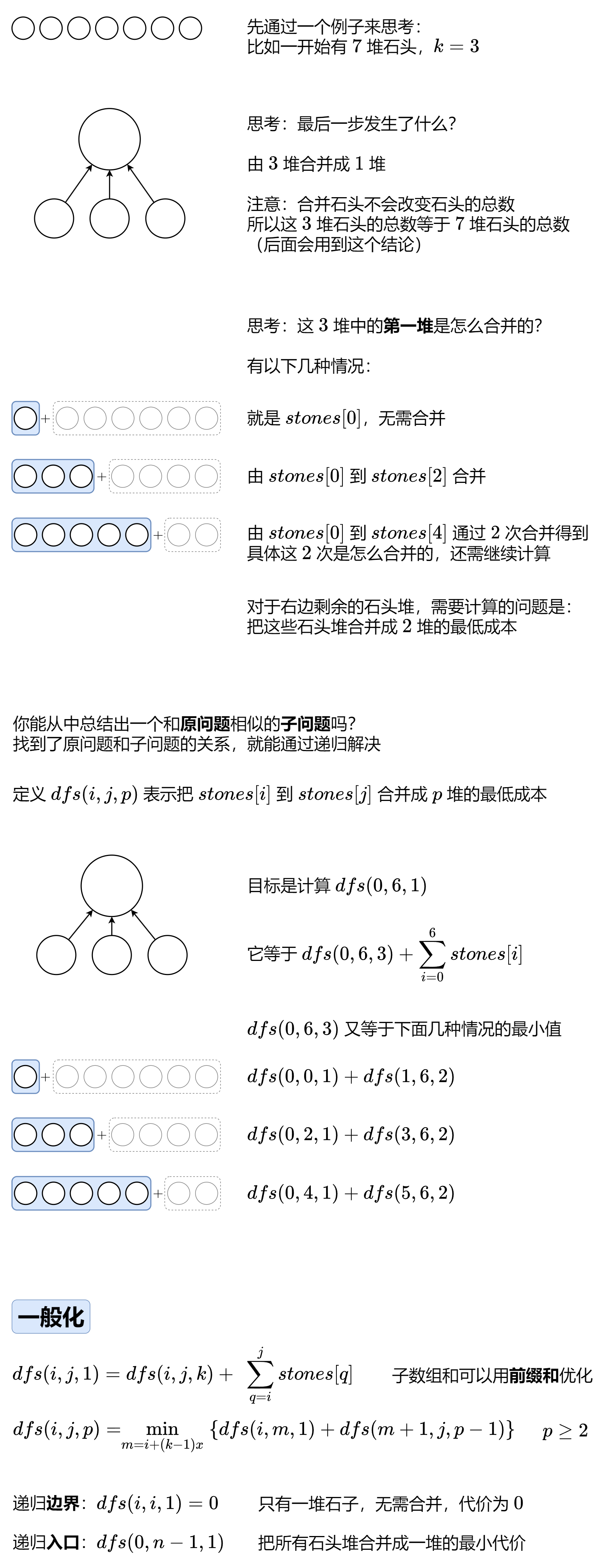
publicintstoneGameVII(int[] stones) { int n=stones.length; int sum[]=newint[n+1]; int momo[][]=newint[n][n]; for (inti=1; i < sum.length; i++) { sum[i]+=sum[i-1]+stones[i-1]; } int res=dfs(0,n-1,sum,momo); return res; } publicintdfs(int begin,int end , int sum[],int mono[][]){ if(begin==end)return0; if(mono[begin][end]>0)return mono[begin][end]; int res1=sum[end+1]-sum[begin+1]-dfs(begin+1,end,sum,mono); int res2=sum[end]-sum[begin]-dfs(begin,end-1,sum,mono); return mono[begin][end]=Math.max(res1,res2); }
public String removeDuplicateLetters(String s) { boolean[] vis = newboolean[26]; int[] num = newint[26]; for (inti=0; i < s.length(); i++) { num[s.charAt(i) - 'a']++; }
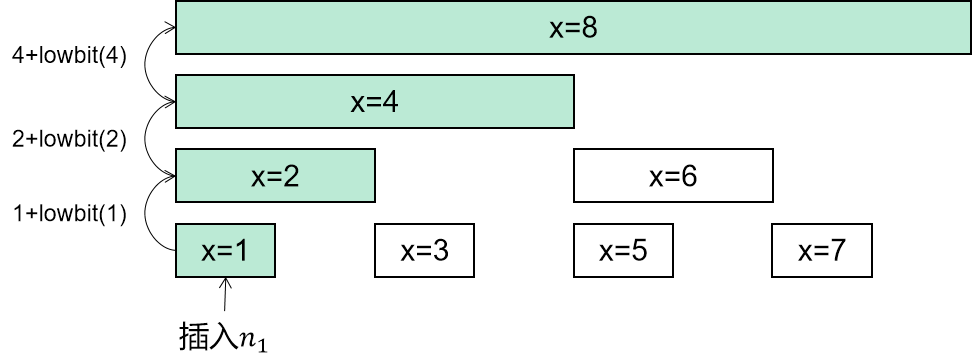
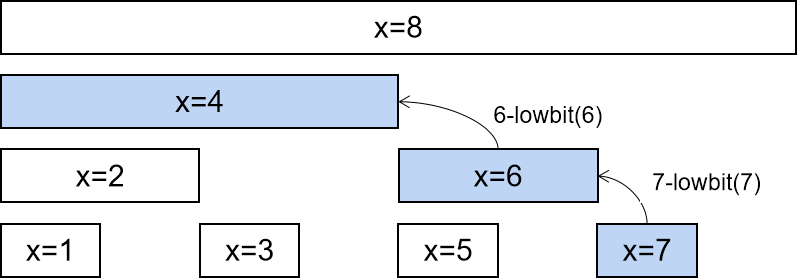
// 并查集初始化 voidinit(){ for (int i = 0; i < n; ++i) { father[i] = i; } } // 并查集里寻根的过程 intfind(int u){ return u == father[u] ? u : father[u] = find(father[u]); } // 将v->u 这条边加入并查集 voidjoin(int u, int v){ u = find(u); v = find(v); if (u == v) return ; father[v] = u; } // 判断 u 和 v是否找到同一个根 boolsame(int u, int v){ u = find(u); v = find(v); return u == v; }
寻找根节点,函数:find(int u),也就是判断这个节点的祖先节点是哪个
将两个节点接入到同一个集合,函数:join(int u, int v),将两个节点连在同一个根节点上
判断两个节点是否在同一个集合,函数:same(int u, int v),就是判断两个节点是不是同一个根节点
//判断有无会议冲突 publicbooleancanAttendMeetings(List<Interval> intervals) { // Write your code here Collections.sort(intervals, (a, b) -> a.start - b.start); for (inti=1; i < intervals.size(); i++) { if (intervals.get(i - 1).end > intervals.get(i).start) { returnfalse; } } returntrue; }
//计算需要的最少的会议房间,此题是一个贪心的思想,通过将开始时间与结束时间分别排序,将开始时间大于结束时间的就可以放一组,如果不是则新开一个房间,这样最终结果就是最小值 publicintminMeetingRooms(List<Interval> intervals) { // Check for the base case. If there are no intervals, return 0 if (intervals.size() == 0) { return0; }
Integer[] start = newInteger[intervals.size()]; Integer[] end = newInteger[intervals.size()];
for (inti=0; i < intervals.size(); i++) { start[i] = intervals.get(i).start; end[i] = intervals.get(i).end; }
// Sort the intervals by end time Arrays.sort( end, newComparator<Integer>() { publicintcompare(Integer a, Integer b) { return a - b; } }); // Sort the intervals by start time Arrays.sort( start, newComparator<Integer>() { publicintcompare(Integer a, Integer b) { return a - b; } }); intstartPointer=0, endPointer = 0; intusedRooms=0; while (startPointer < intervals.size()) { if (start[startPointer] >= end[endPointer]) { usedRooms -= 1; endPointer += 1; } usedRooms += 1; startPointer += 1;
//取模性质 (a + b) % p = (a % p + b % p) % p (1) (a - b) % p = (a % p - b % p ) % p (2) (a * b) % p = (a % p * b % p) % p (3) a ^ b % p = ((a % p)^b) % p (4) //递归 long c=10000007; publiclongdivide(long a, long b) { if (b == 0) return1; elseif (b % 2 == 0) //偶数情况 return divide((a % c) * (a % c), b / 2) % c; else//奇数情况 return a % c * divide((a % c) * (a % c), (b - 1) / 2) % c; } //非递归 longc=1000000007; publiclongdivide(long a, long b) { a %= c; longres=1; for (; b != 0; b /= 2) { if (b % 2 == 1) res = (res * a) % c; a = (a * a) % c; } return res; } longlongintquik_power(int base, int power) { longlongintresult=1; while (power > 0) //指数大于0进行指数折半,底数变其平方的操作 { if (power & 1) //指数为奇数,power & 1这相当于power % 2 == 1 result *= base; //分离出当前项并累乘后保存 power >>= 1; //指数折半,power >>= 1这相当于power /= 2; base *= base; //底数变其平方 } return result; //返回最终结果 }
publicint[] divisibilityArray(String word, int m) { int res[]=newint[word.length()]; long cur=0; for (inti=0; i < word.length(); i++) { char c=word.charAt(i); cur=cur*10+Integer.valueOf(i); System.out.println(cur); if(cur%m==0)res[i]=1; else res[i]=0; } return res; }
publicintfindKthNumber(int n, int k) { intans=1; while (k > 1) { intcnt= getCnt(ans, n); if (cnt < k) { k -= cnt; ans++; } else { k--; ans *= 10; } } return ans; } intgetCnt(int x, int limit) { Stringa= String.valueOf(x), b = String.valueOf(limit); intn= a.length(), m = b.length(), k = m - n; intans=0, u = Integer.parseInt(b.substring(0, n)); for (inti=0; i < k; i++) ans += Math.pow(10, i); if (u > x) ans += Math.pow(10, k); elseif (u == x) ans += limit - x * Math.pow(10, k) + 1; return ans; }
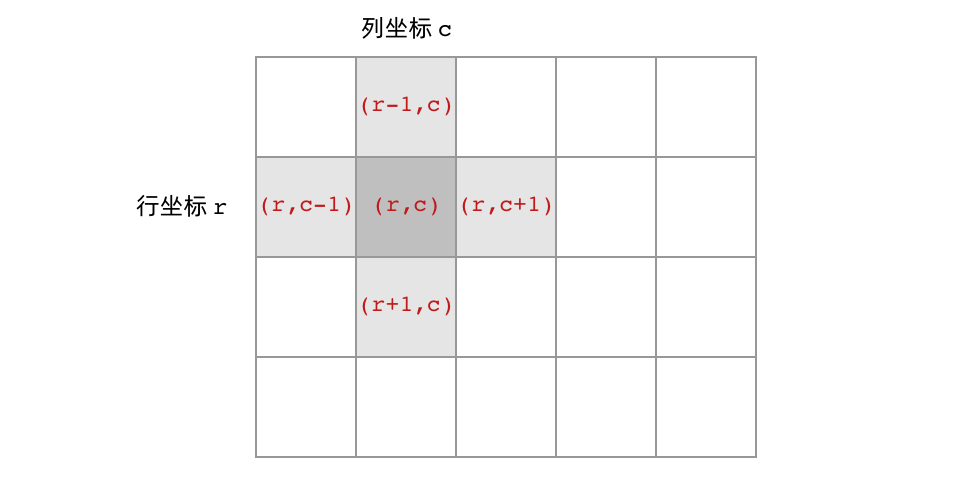
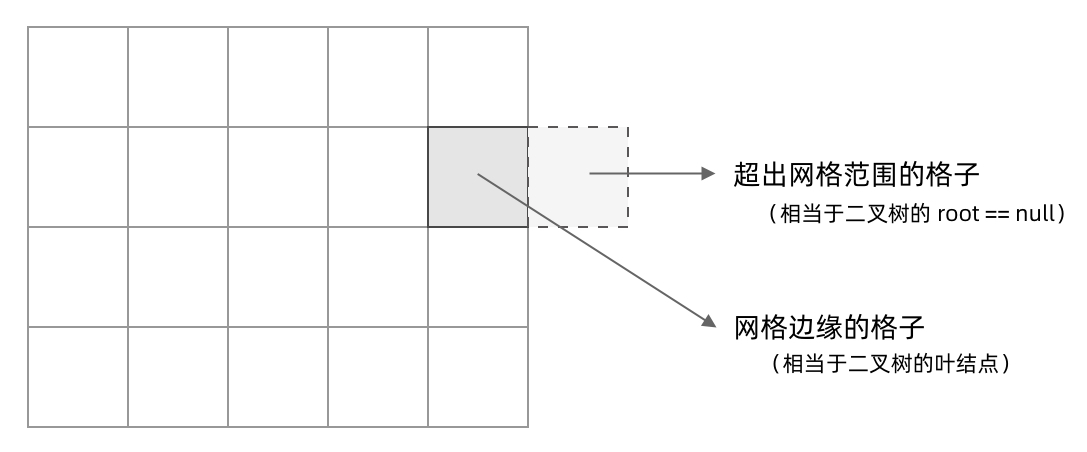
voiddfs(int[][] grid, int r, int c) { // 判断 base case // 如果坐标 (r, c) 超出了网格范围,直接返回 if (!inArea(grid, r, c)) { return; } // 访问上、下、左、右四个相邻结点 dfs(grid, r - 1, c); dfs(grid, r + 1, c); dfs(grid, r, c - 1); dfs(grid, r, c + 1); }
// 判断坐标 (r, c) 是否在网格中 booleaninArea(int[][] grid, int r, int c) { return0 <= r && r < grid.length && 0 <= c && c < grid[0].length; }
for (inti=0; i < m; i++) { dfs3(pacific,i, 0, heights); } for (intj=1; j < n; j++) { dfs3(pacific,0, j, heights); } for (inti=0; i < m; i++) { dfs3(atlantic,i, n - 1,heights ); } for (intj=0; j < n - 1; j++) { dfs3(atlantic,m - 1, j, heights); }
publicvoiddfs3(boolean [][]ocean,int i,int j,int [][]height){ if(ocean[i][j])return; ocean[i][j]=true; for (int[] dir : dirs) { int newi=i+dir[0],newj=j+dir[1]; if(newi>=0 && newi<height.length && newj>=0 && newj<height[0].length && height[newi][newj]>=height[i][j]) dfs3(ocean,newi,newj,height); } }
publicintrootCount(int[][] edges, int[][] guesses, int k) { this.k = k; times = newArrayList[edges.length + 1]; Arrays.setAll(times, i -> newArrayList<>()); for (int[] e : edges) { intx= e[0]; inty= e[1]; times[x].add(y); times[y].add(x); // 建图 }
for (int[] e : guesses) { // guesses 转成哈希表 s.add((long) e[0] << 32 | e[1]); // 两个 4 字节 int 压缩成一个 8 字节 long }
dfs(0, -1); reroot(0, -1, cnt0); return res; }
privatevoiddfs(int x, int fa) { for (int y : times[x]) { if (y != fa) { if (s.contains((long) x << 32 | y)) { // 以 0 为根时,猜对了 cnt0++; } dfs(y, x); } } }
privatevoidreroot(int x, int fa, int cnt) { if (cnt >= k) { // 此时 cnt 就是以 x 为根时的猜对次数 res++; } for (int y : times[x]) { if (y != fa) { intc= cnt; if (s.contains((long) x << 32 | y)) c--; // 原来是对的,现在错了 if (s.contains((long) y << 32 | x)) c++; // 原来是错的,现在对了 reroot(y, x, c); } } }
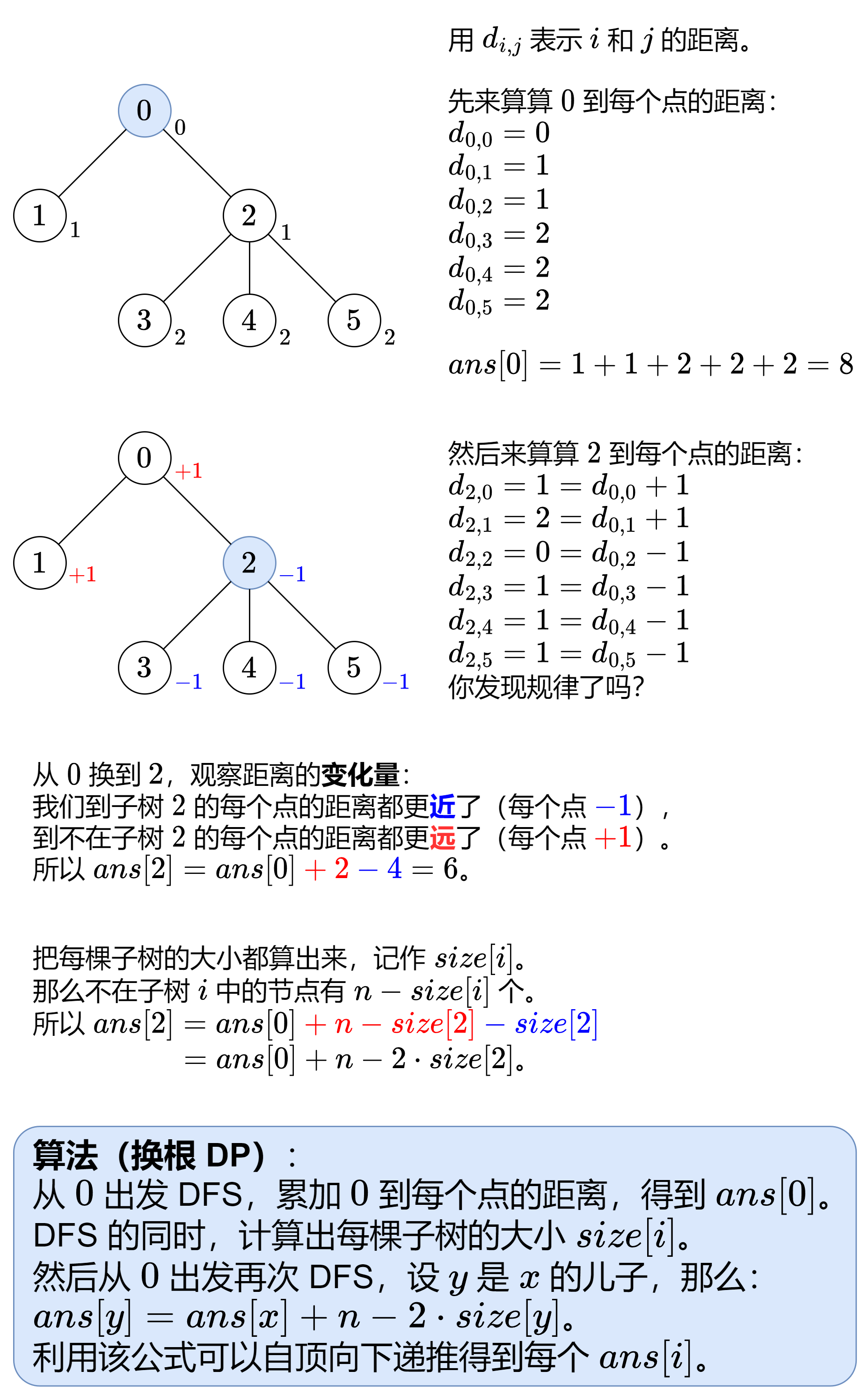
//834. 树中距离之和 https://leetcode.cn/problems/sum-of-distances-in-tree/description/ private List<Integer>[] g; privateint[] ans, size; publicint[] sumOfDistancesInTree(int n, int[][] edges) { g = newArrayList[n]; // g[x] 表示 x 的所有邻居 Arrays.setAll(g, e -> newArrayList<>()); for (int [] e : edges) { intx= e[0], y = e[1]; g[x].add(y); g[y].add(x); } ans = newint[n]; size = newint[n]; dfs(0, -1, 0); // 0 没有父节点 reroot(0, -1); // 0 没有父节点 return ans; }
privatevoiddfs(int x, int fa, int depth) { ans[0] += depth; // depth 为 0 到 x 的距离 size[x] = 1; for (int y : g[x]) { // 遍历 x 的邻居 y if (y != fa) { // 避免访问父节点 dfs(y, x, depth + 1); // x 是 y 的父节点 size[x] += size[y]; // 累加 x 的儿子 y 的子树大小 } } }
privatevoidreroot(int x, int fa) { for (int y : g[x]) { // 遍历 x 的邻居 y if (y != fa) { // 避免访问父节点 ans[y] = ans[x] + g.length - 2 * size[y]; reroot(y, x); // x 是 y 的父节点 } } }
notice: you can omit the super when you call the no parameter method but if you call the method with parameter you must call the right super(x)with the right parameter.
We’ve seen interfaces that can do a lot of cool things! They allow you to take advantage of interface inheritance and implementation inheritance. As a refresher, these are the qualities of interfaces:
All methods must be public.
All variables must be public static final.
Cannot be instantiated
All methods are by default abstract unless specified to be default
Can implement more than one interface per class
Below are the characteristics of abstract classes:
Methods can be public or private
Can have any types of variables
Cannot be instantiated
Methods are by default concrete unless specified to be abstract
Welcome to Hexo! This is your very first post. Check documentation for more info. If you get any problems when using Hexo, you can find the answer in troubleshooting or you can ask me on GitHub.






































.png)


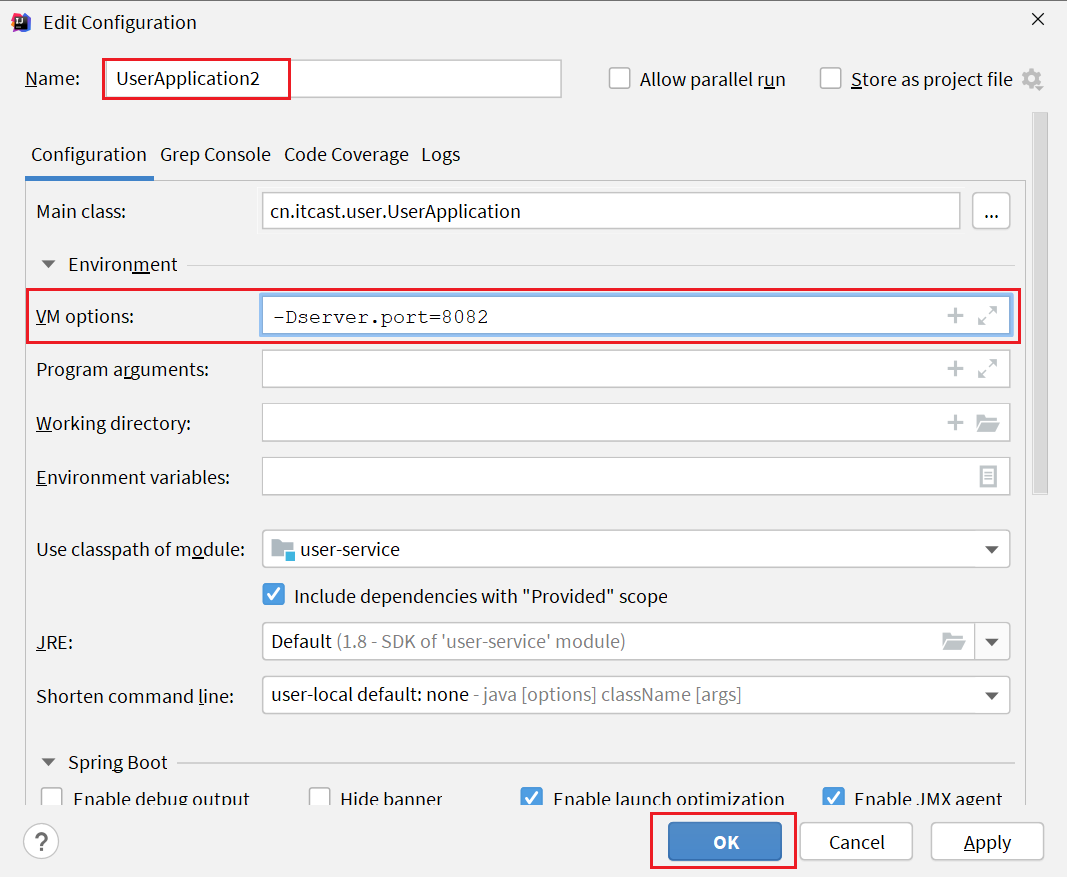

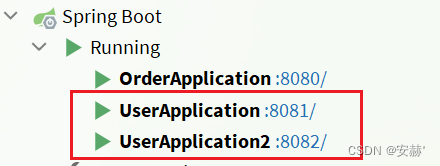

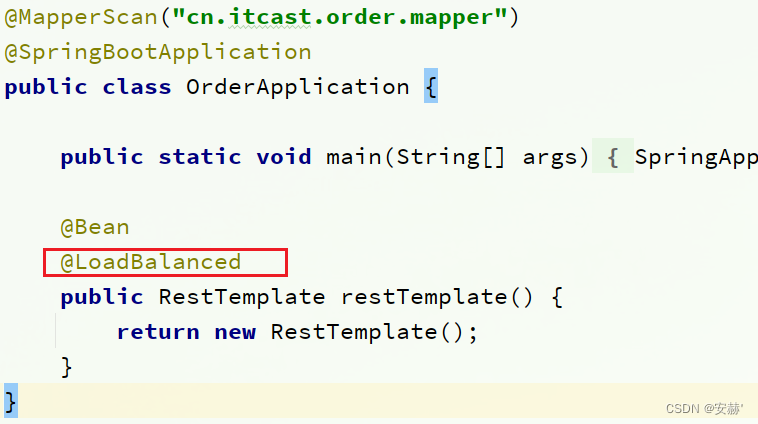
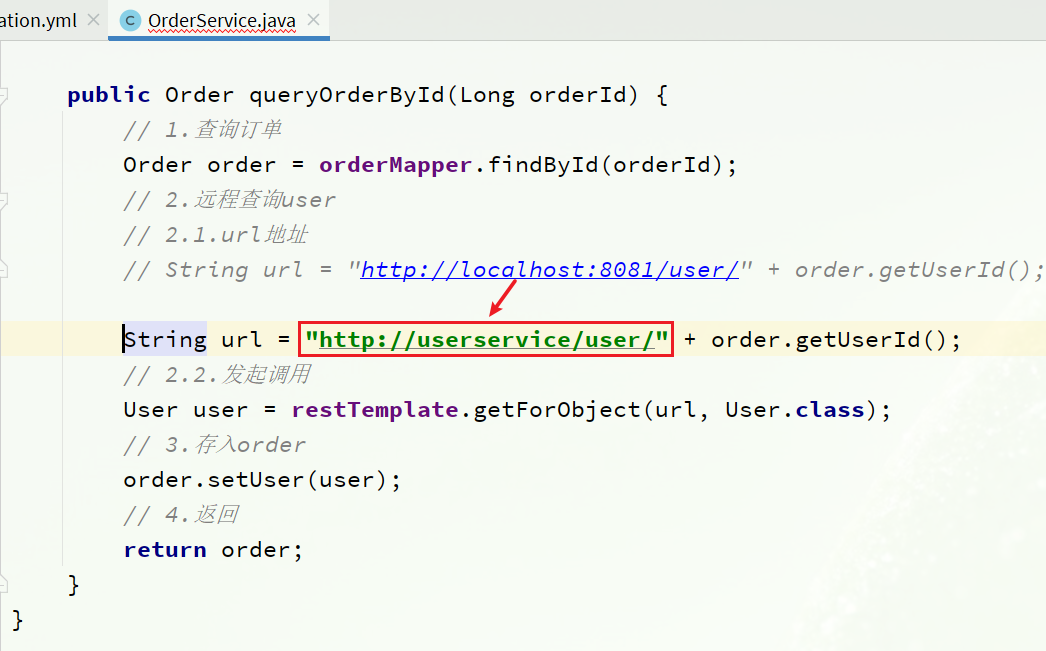
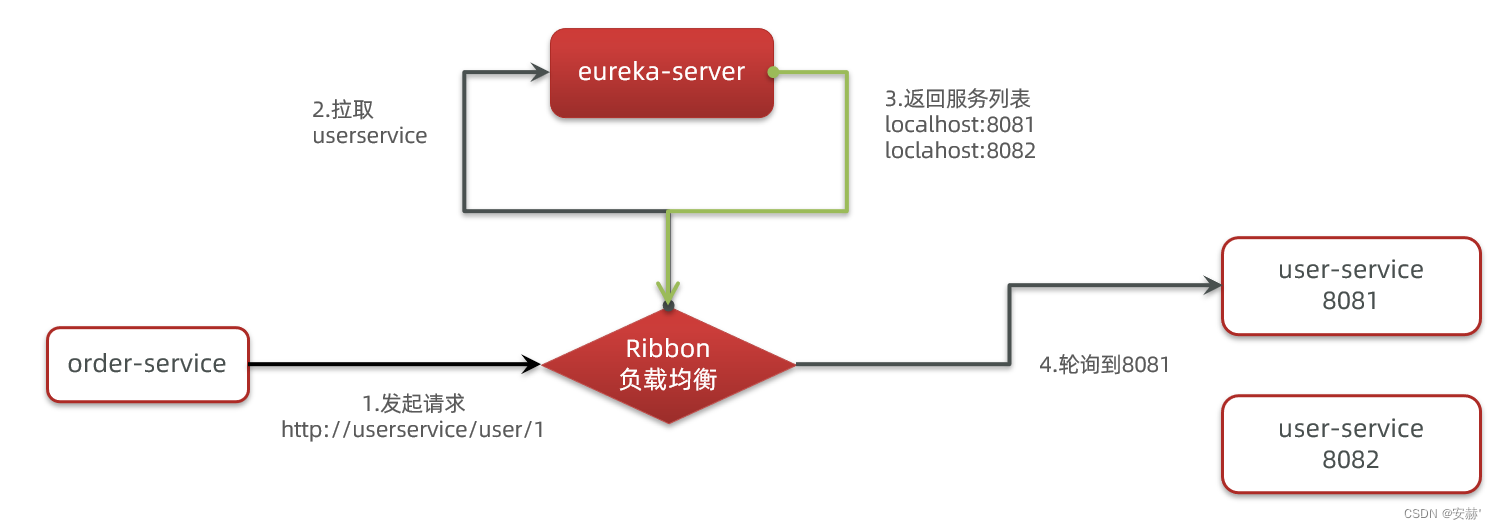
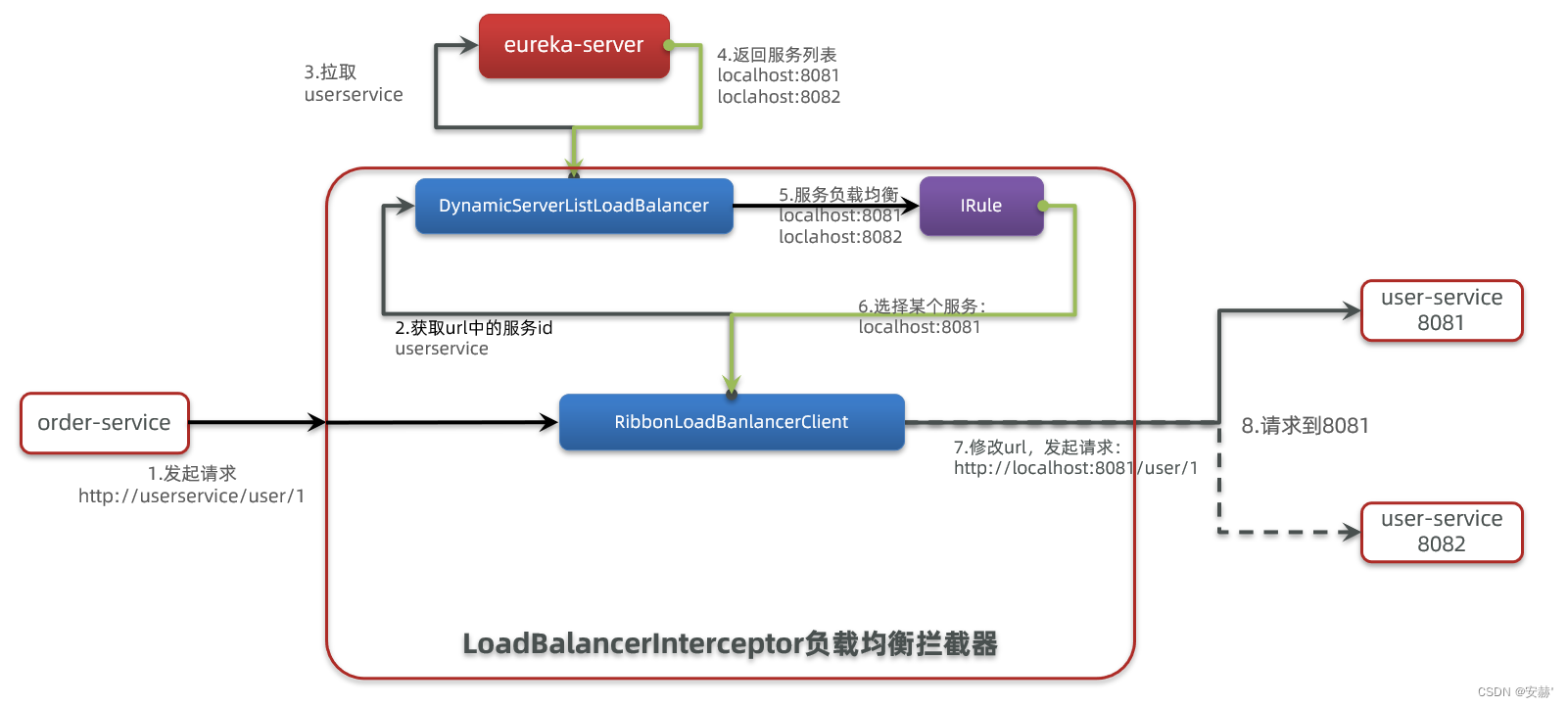
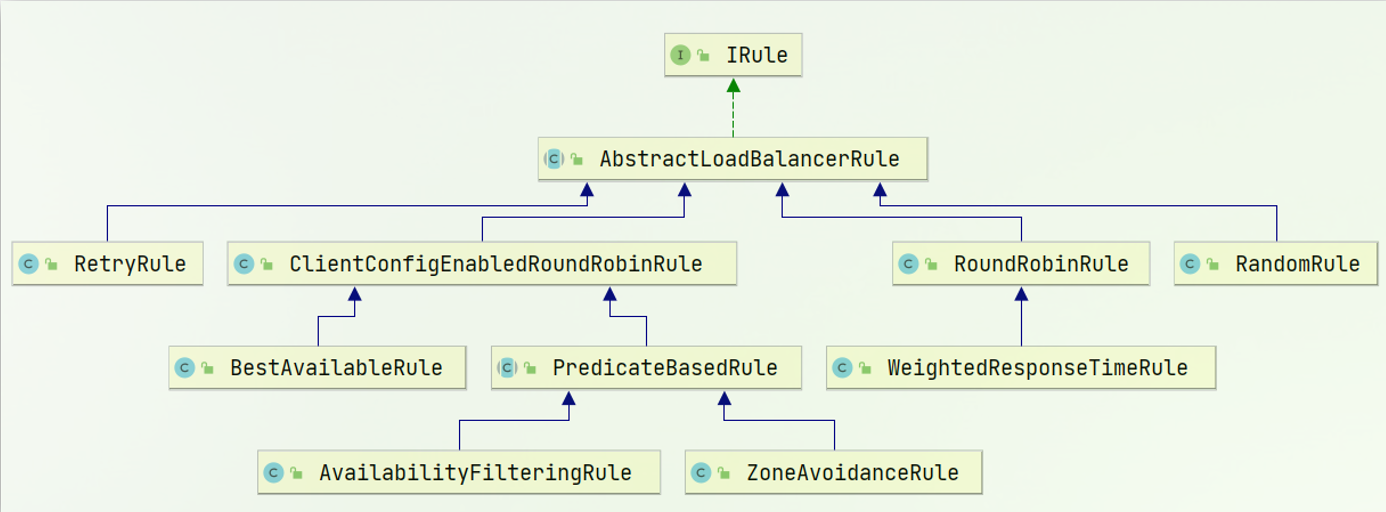

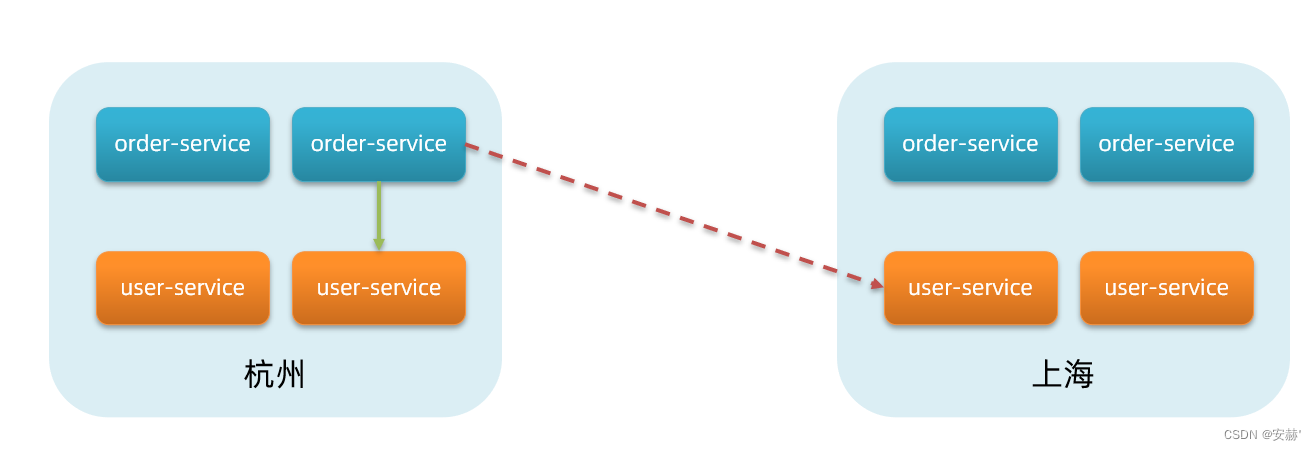

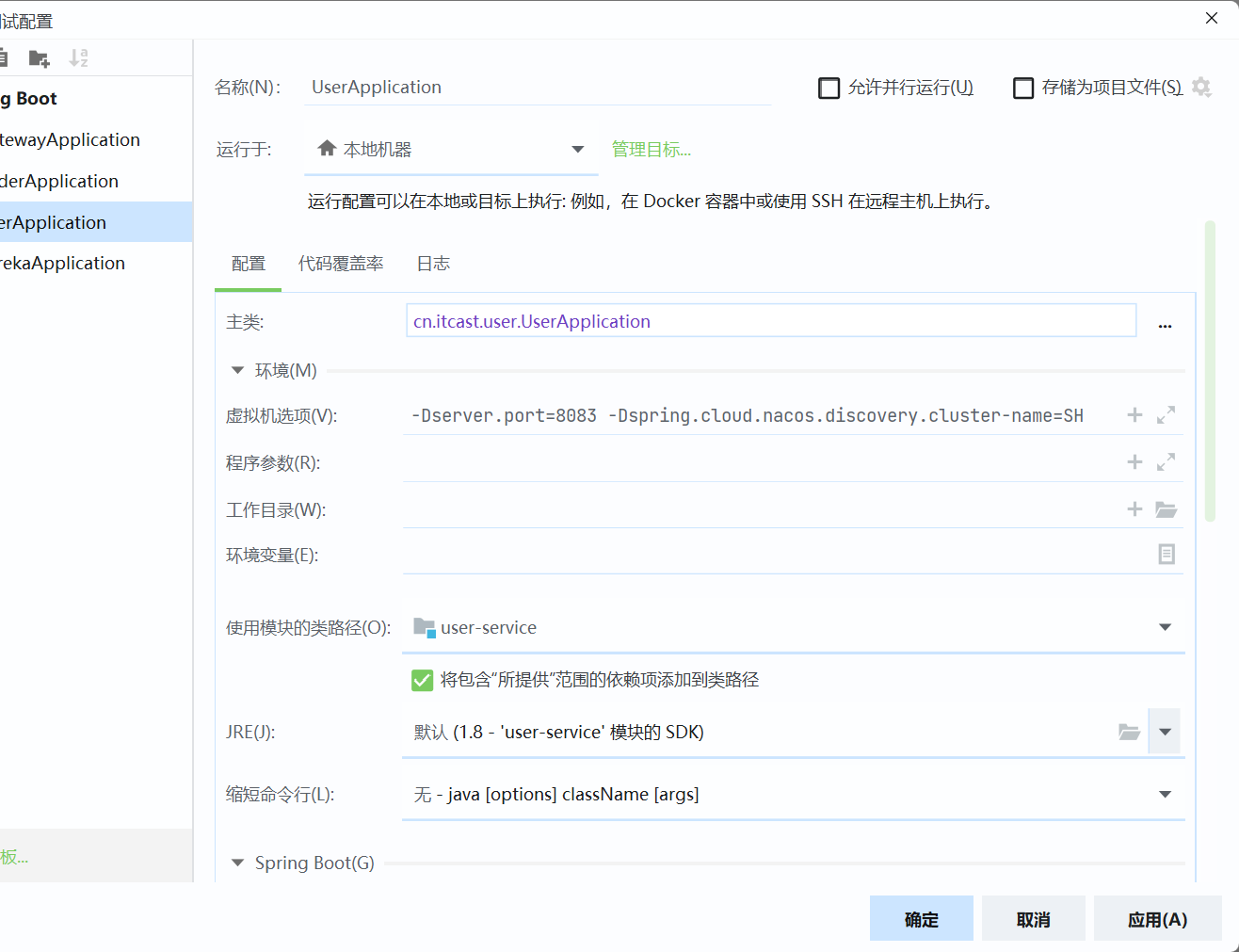
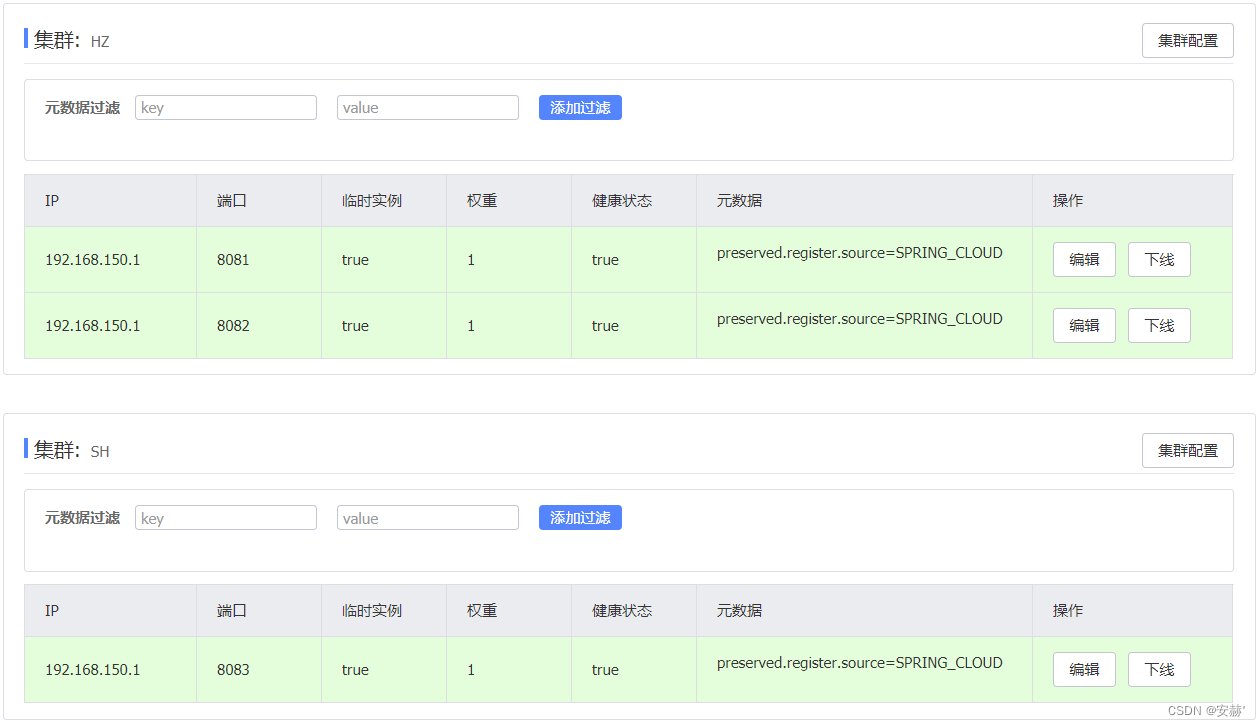
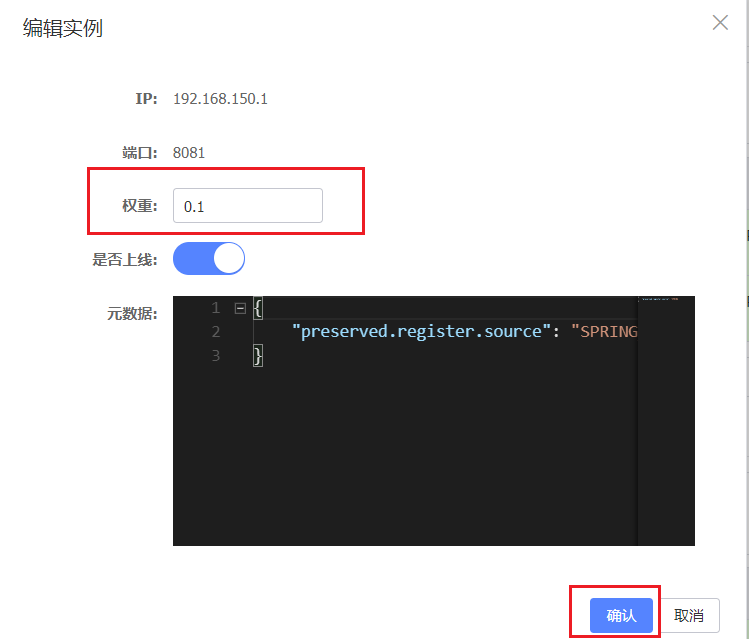


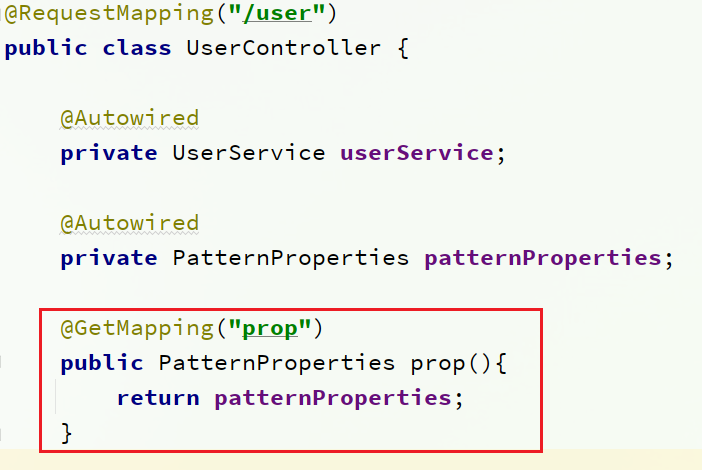
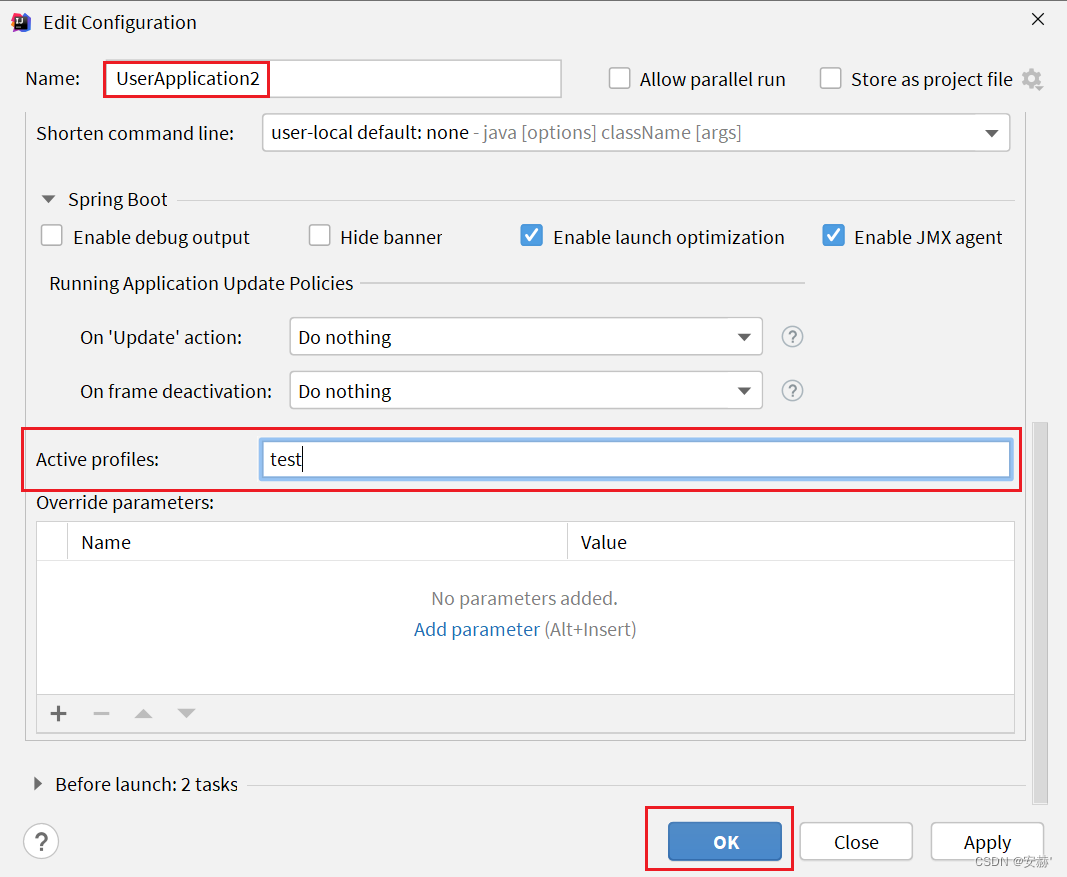
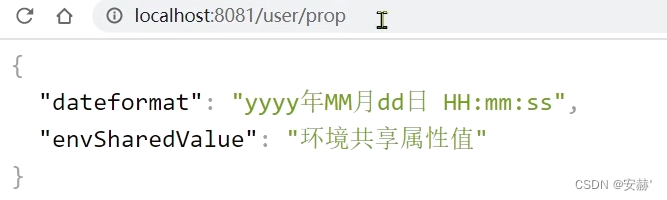


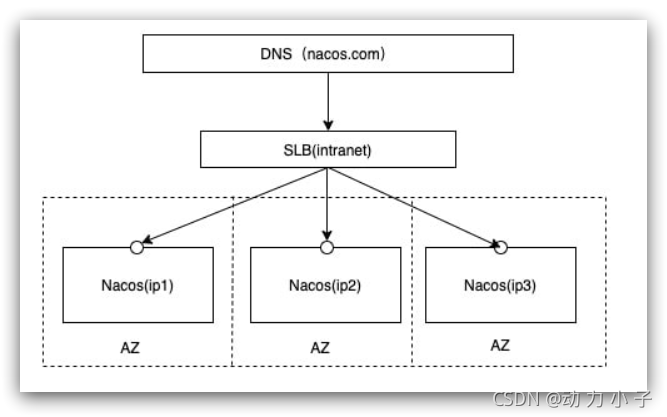








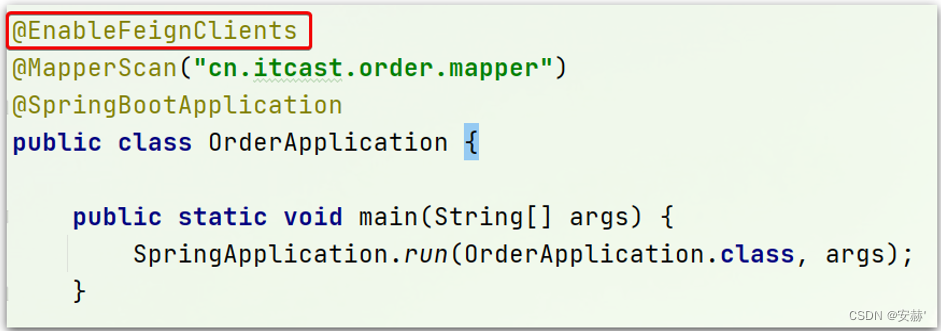
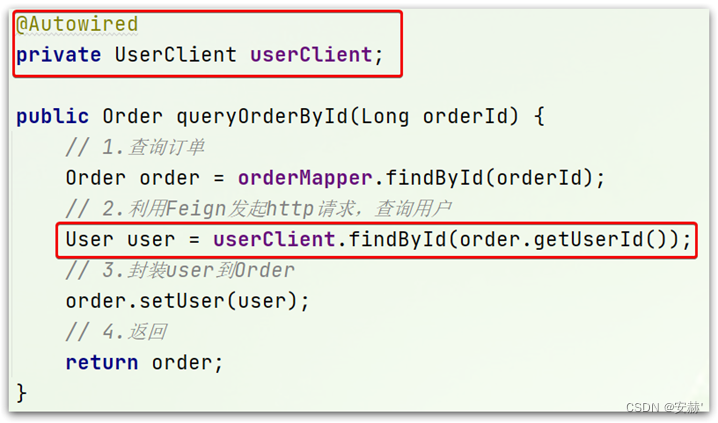
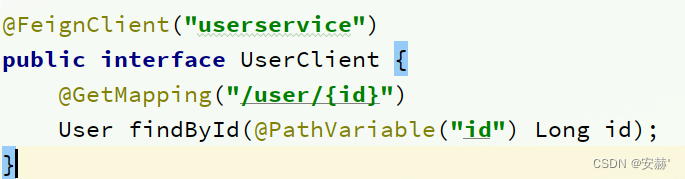
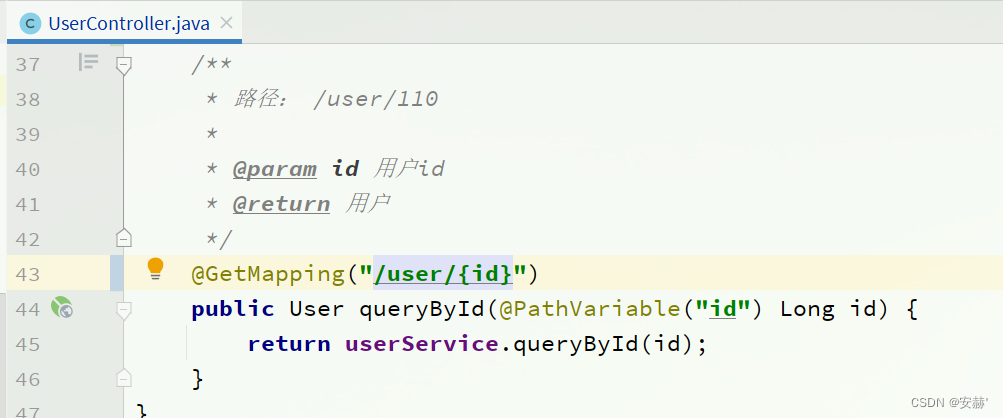
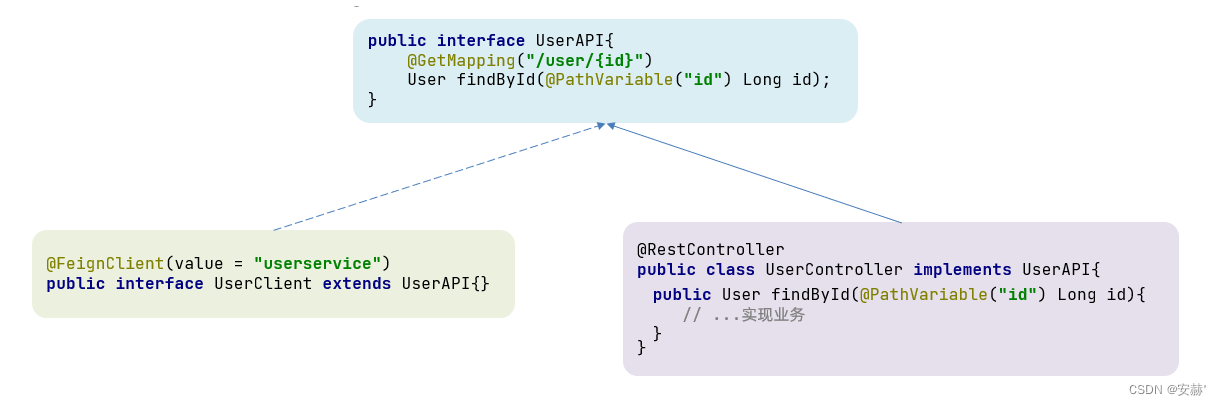
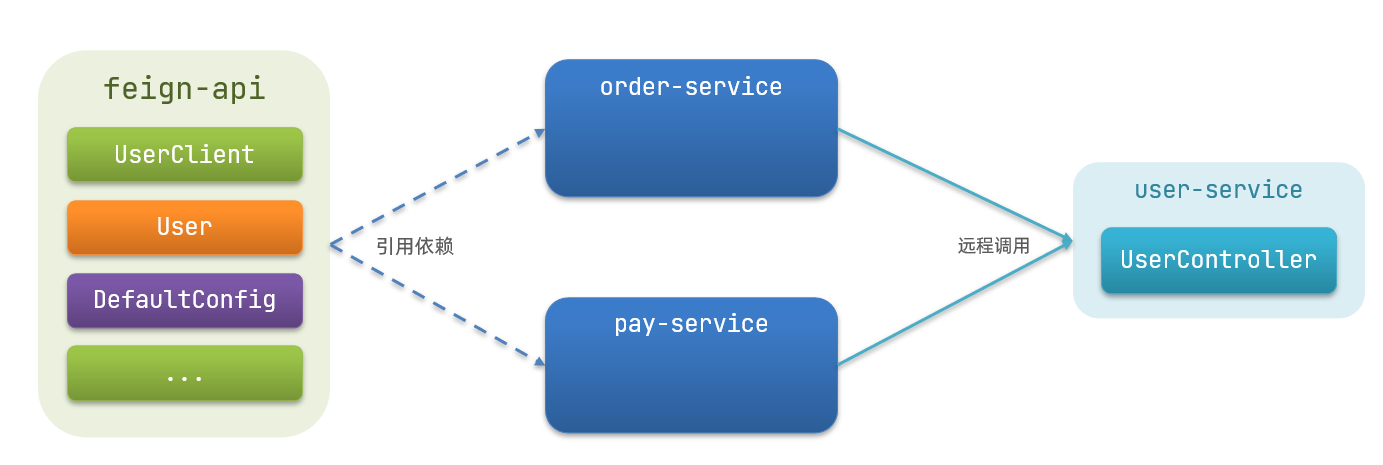
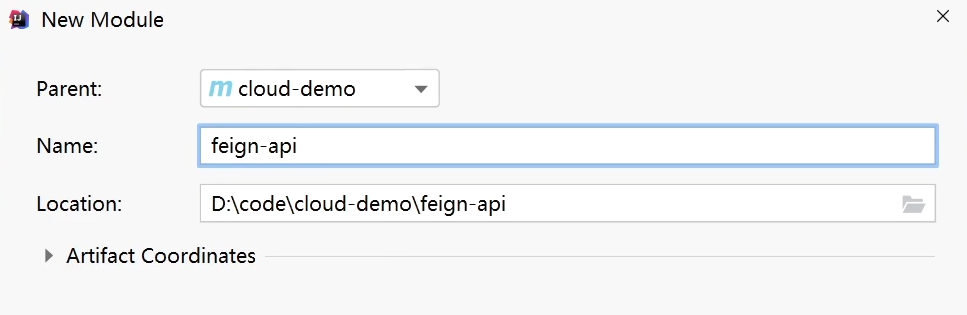
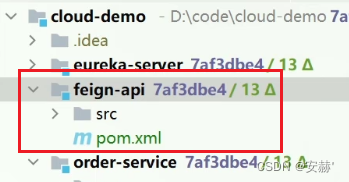


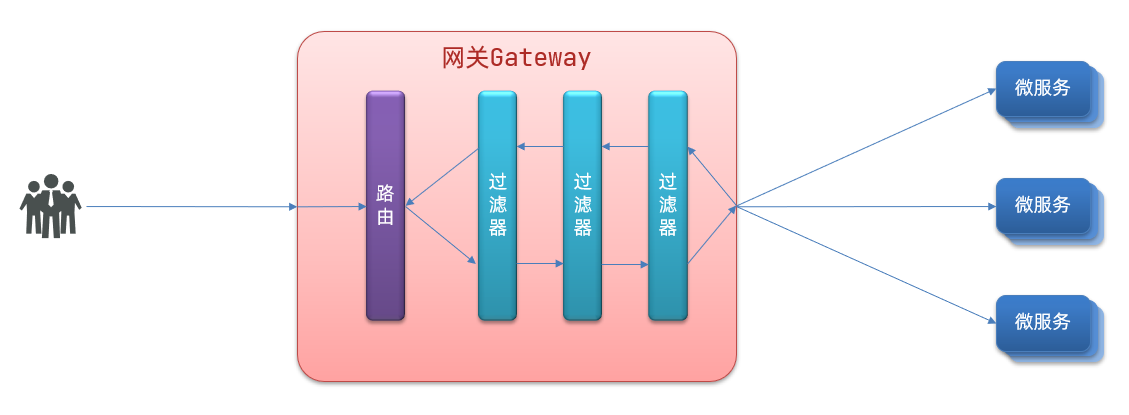

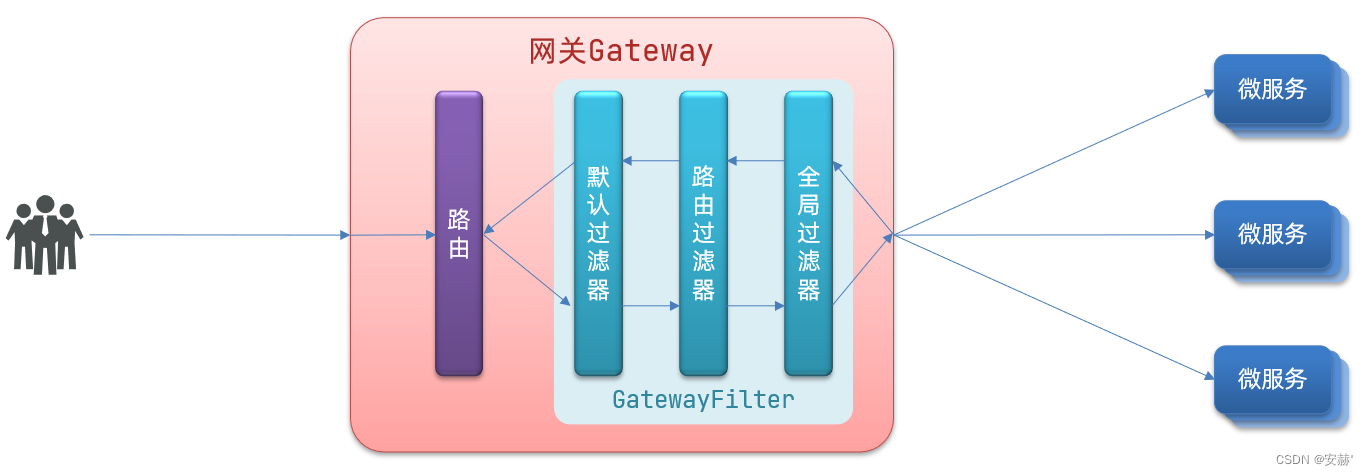

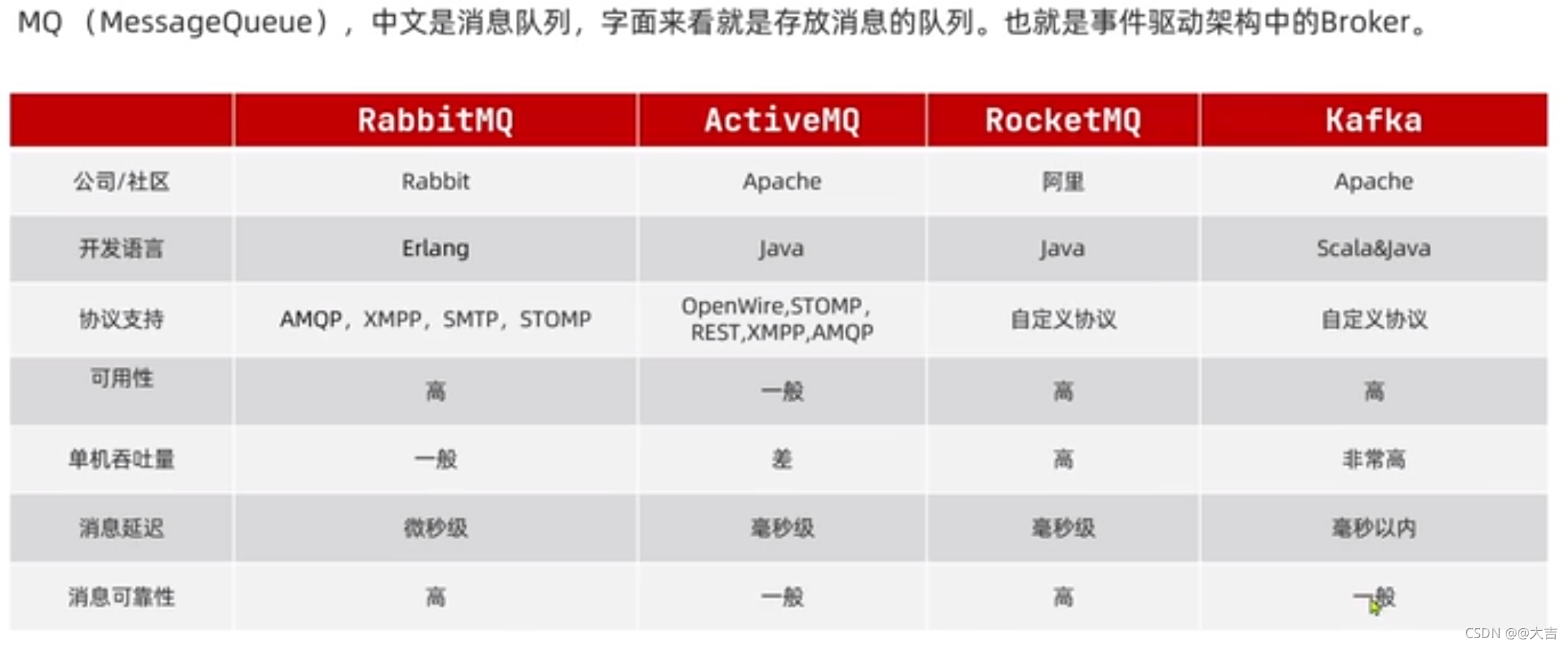
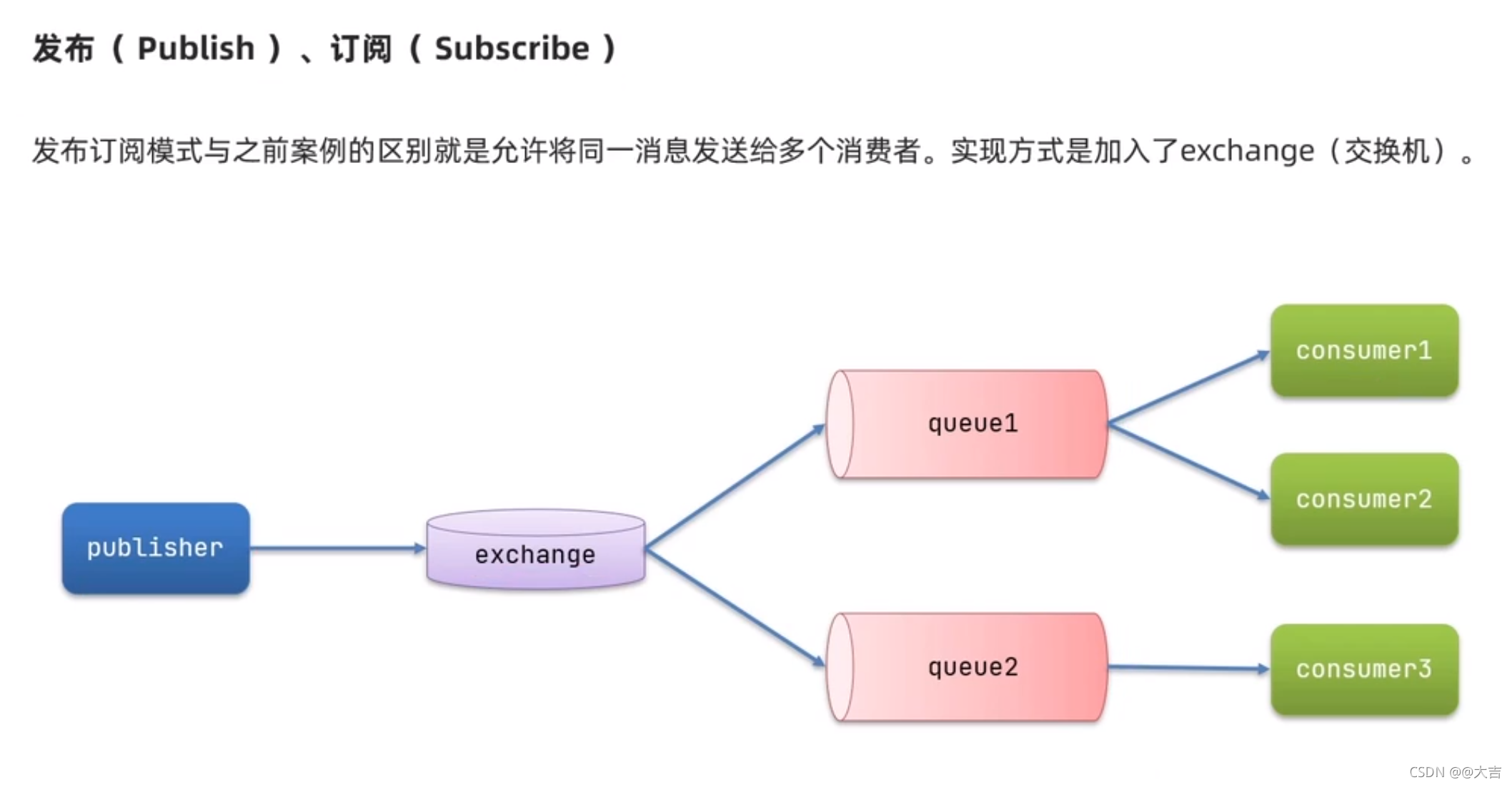
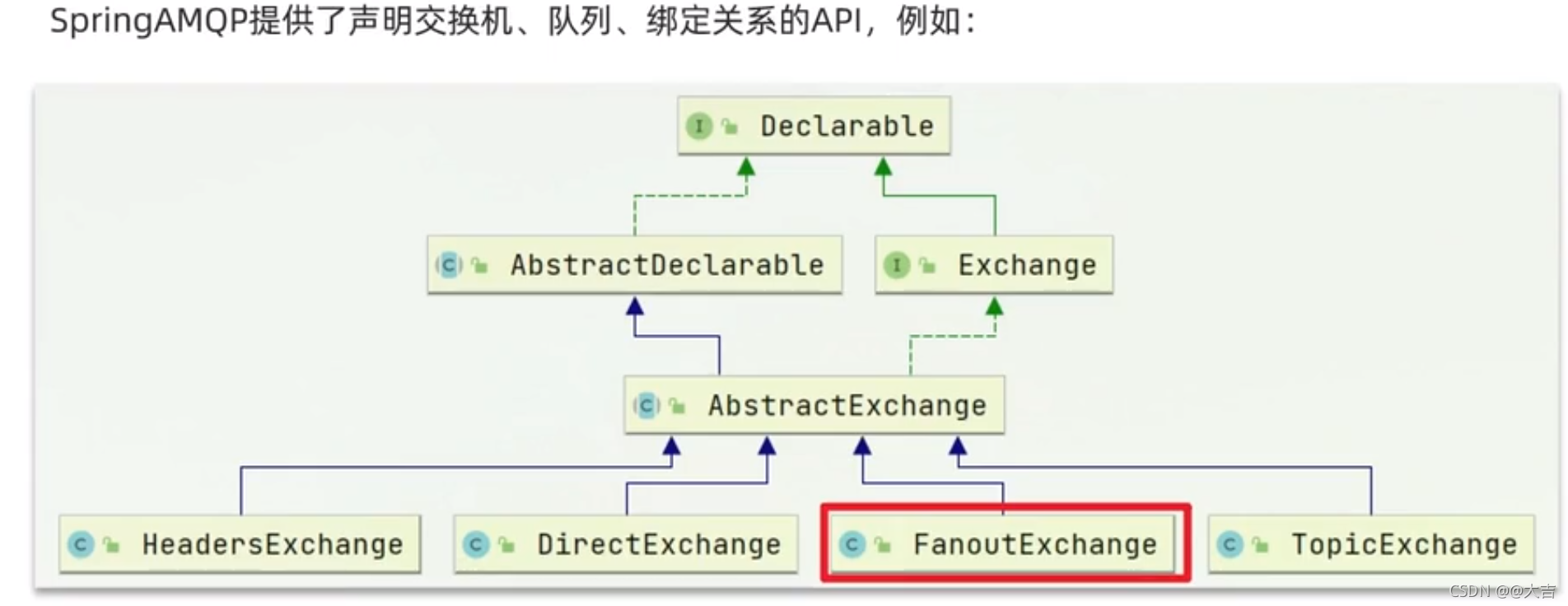


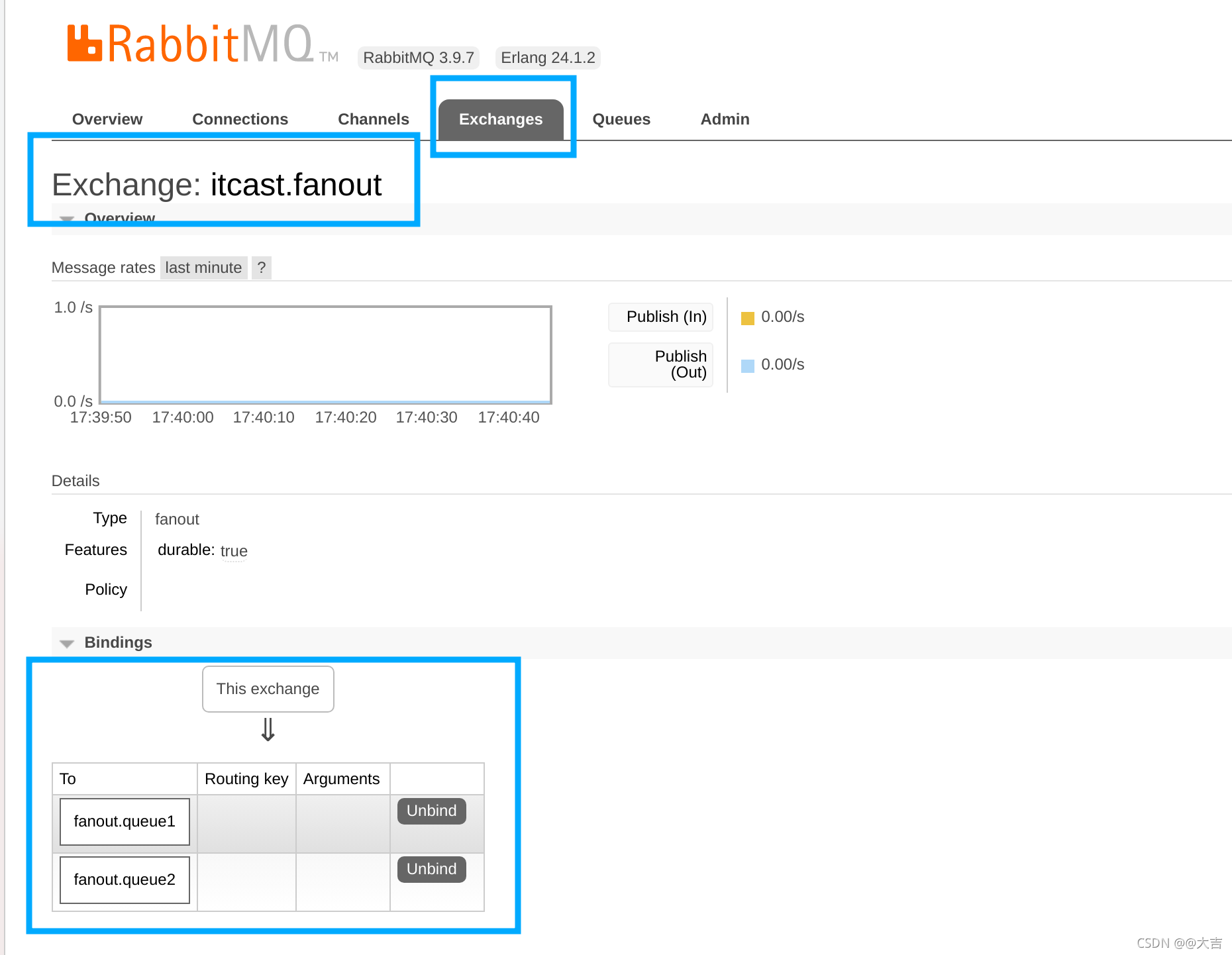
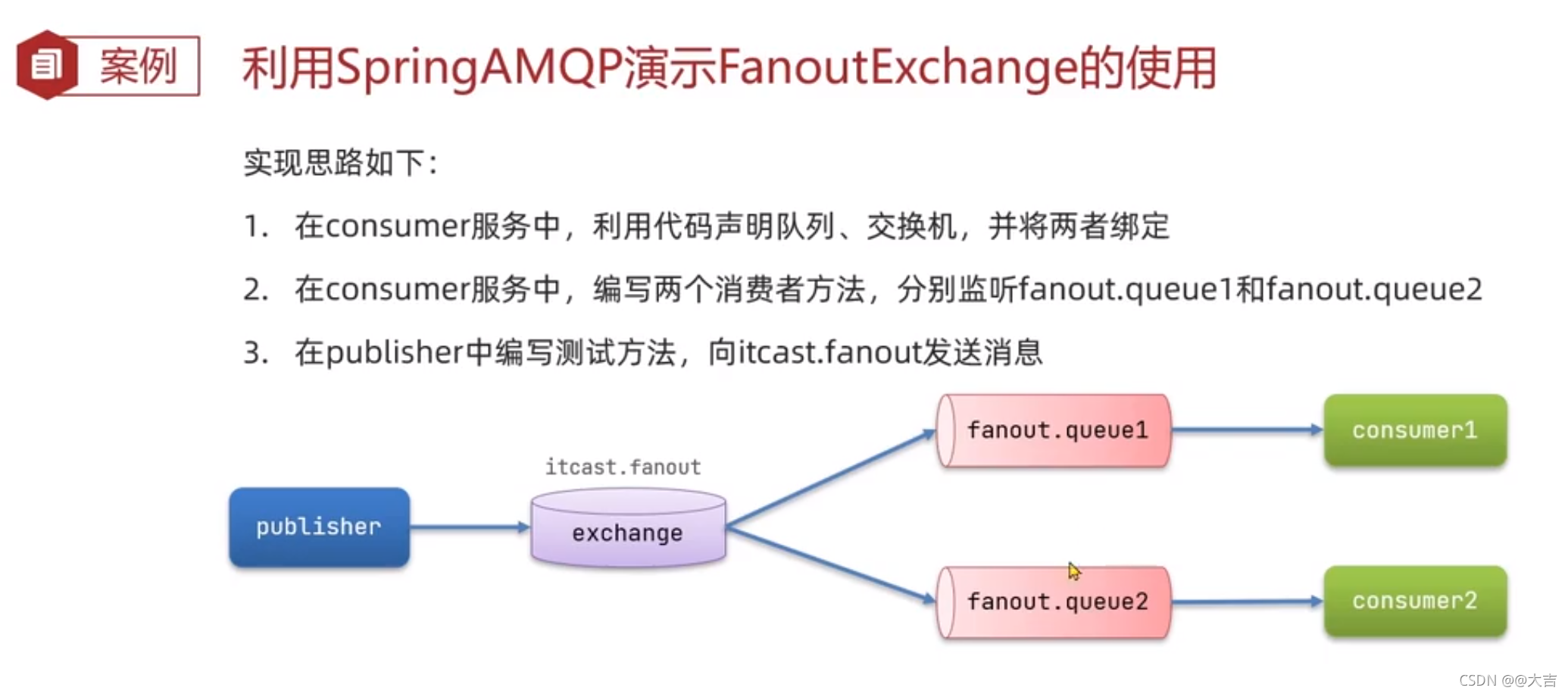
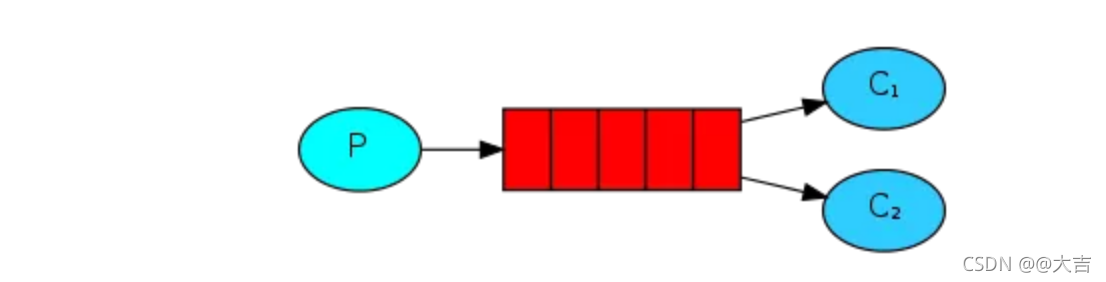
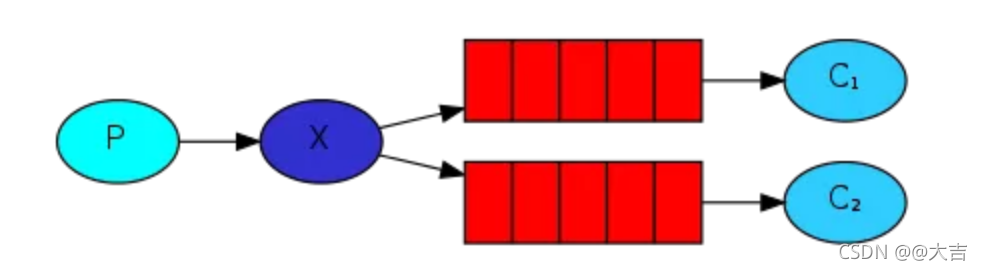
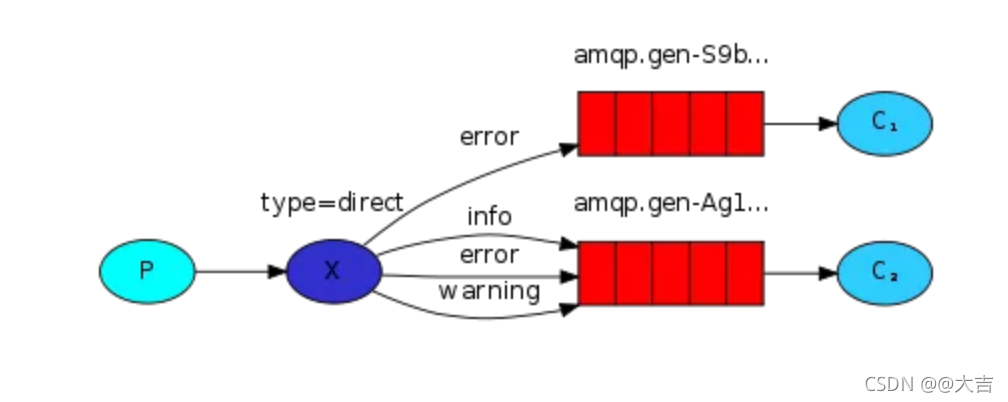
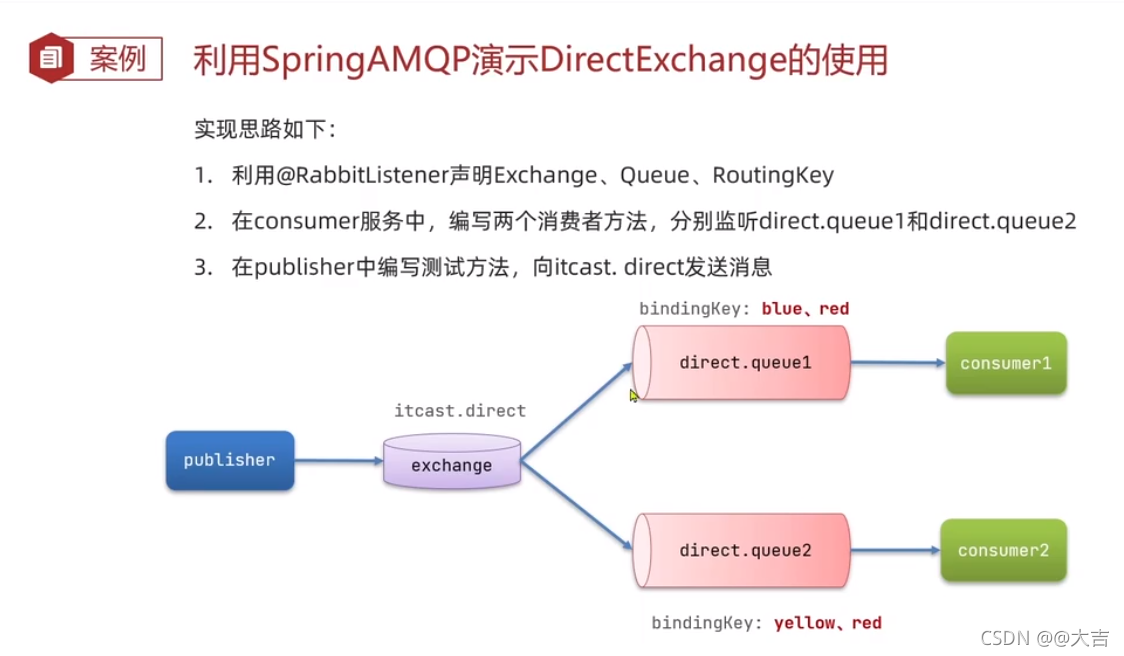
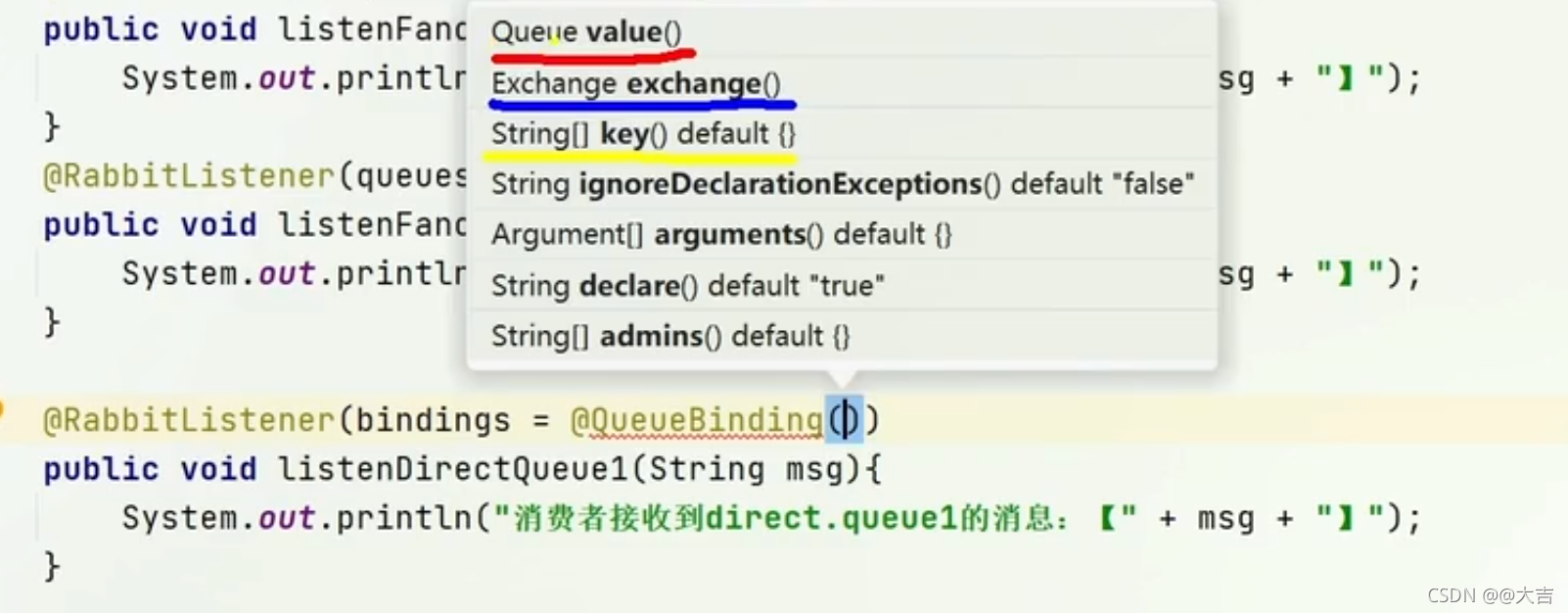
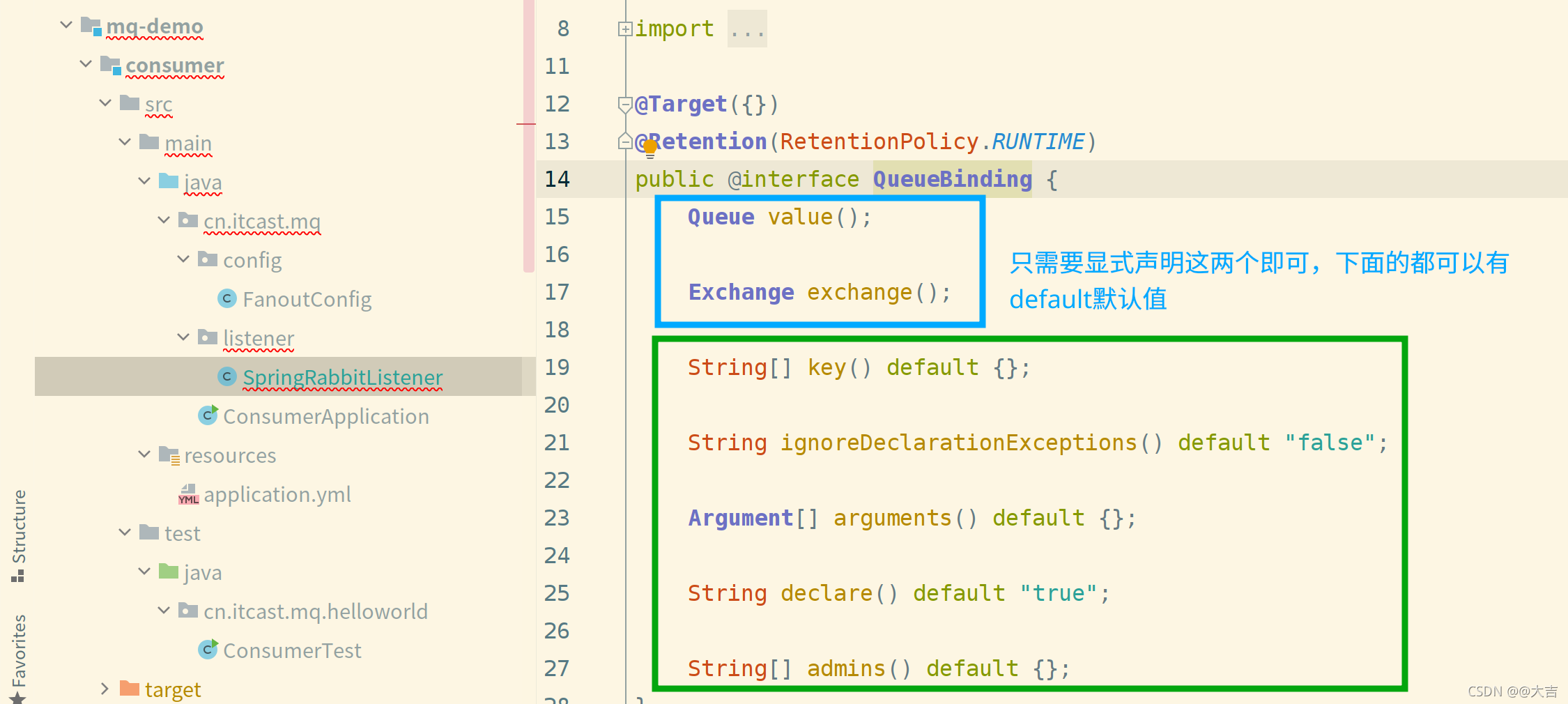

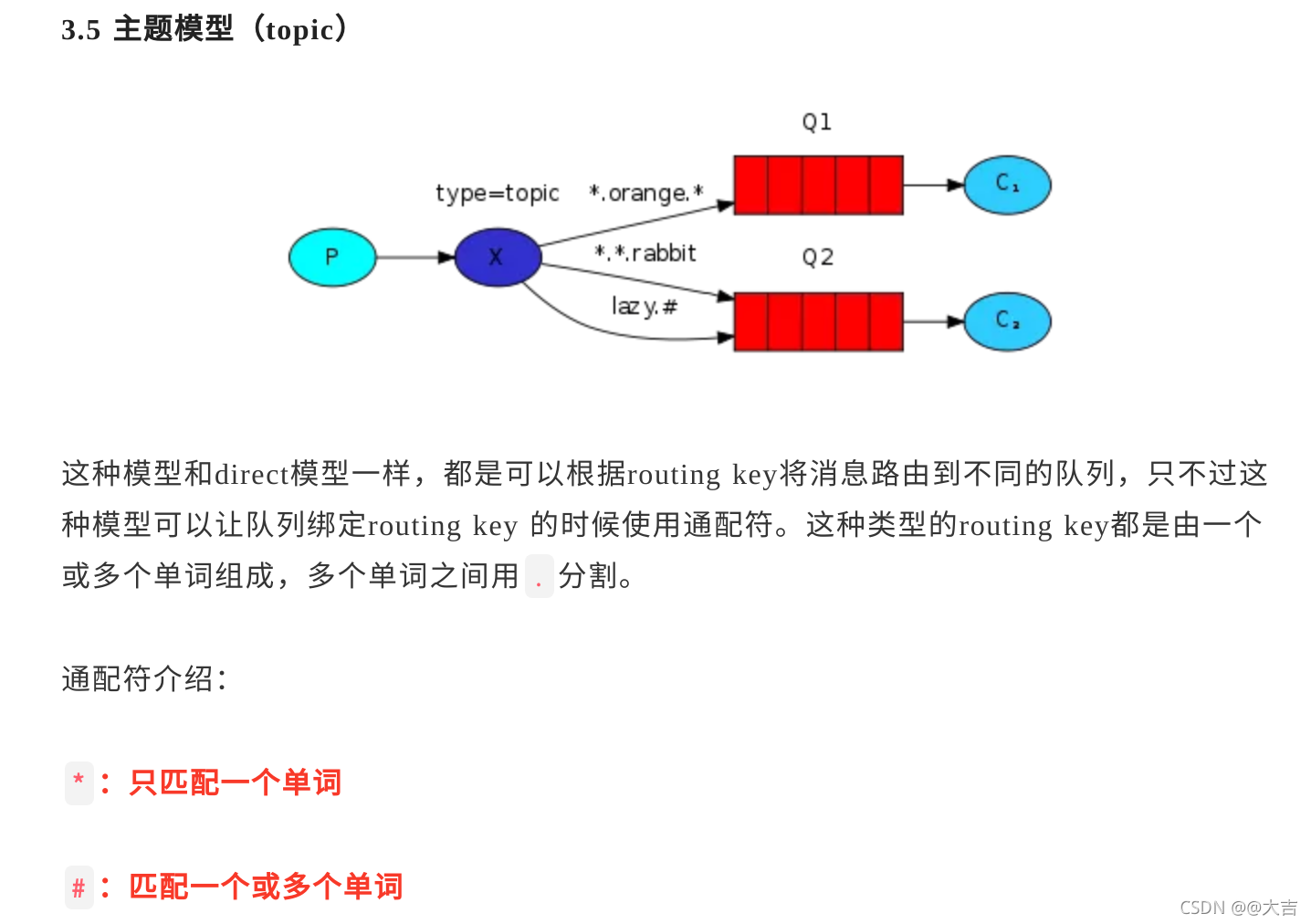
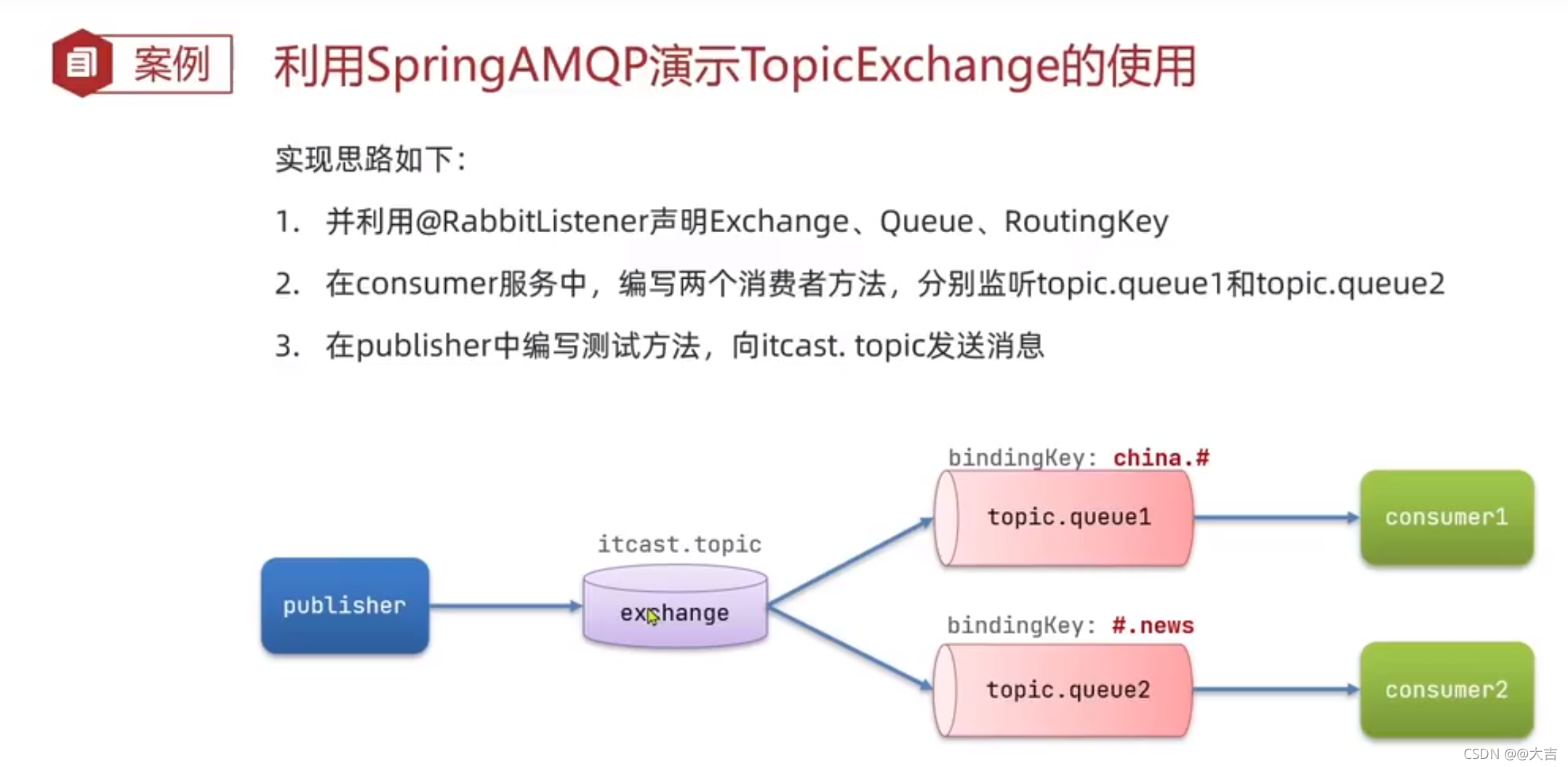
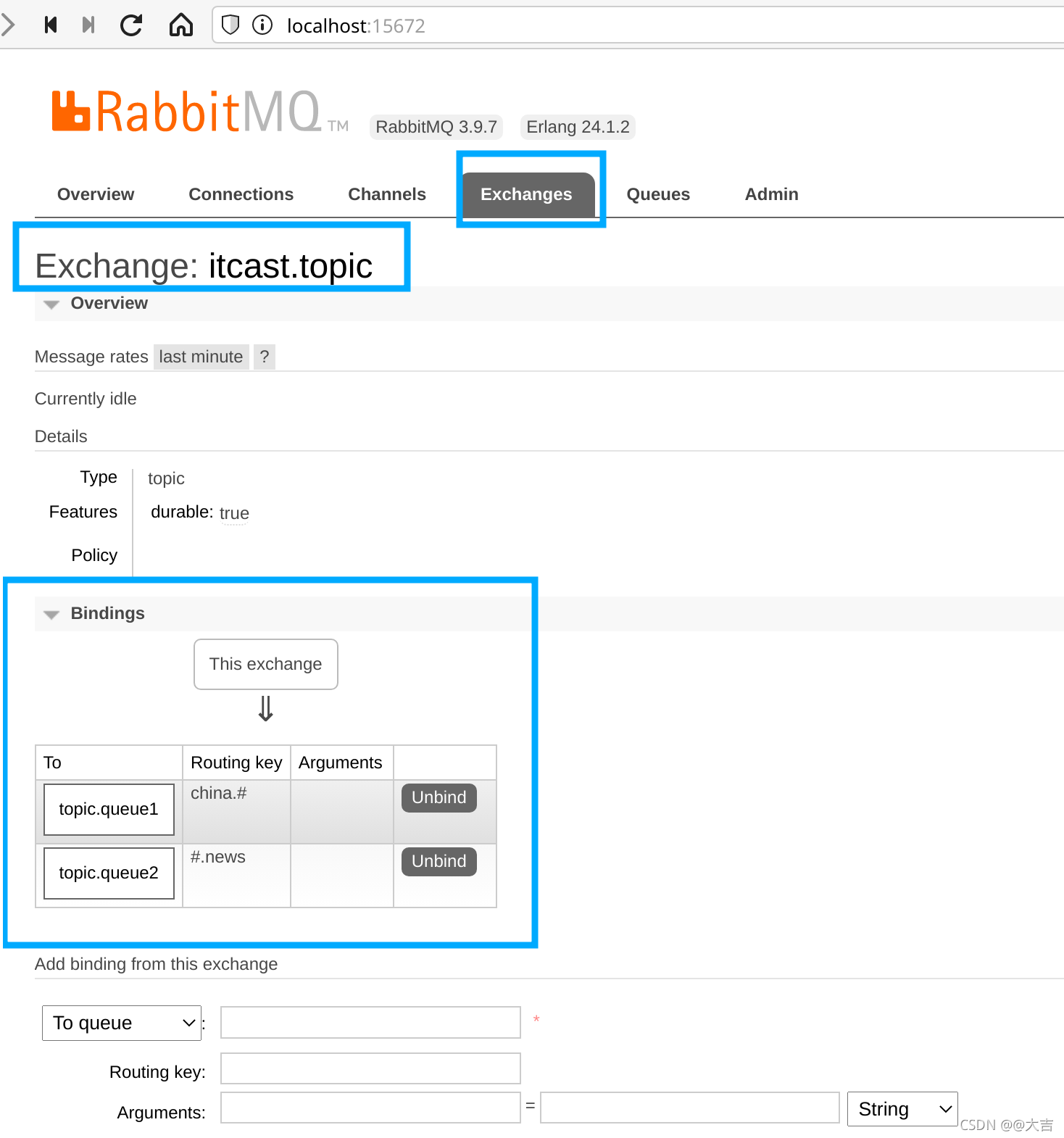
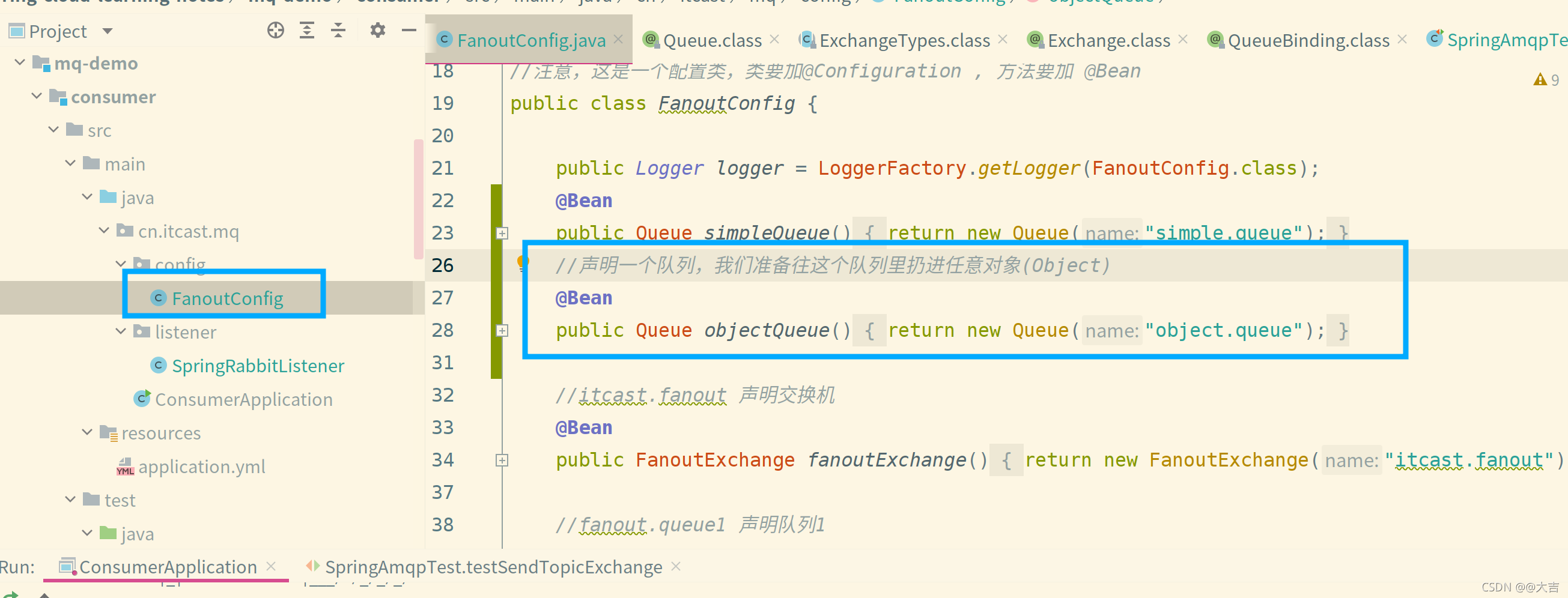
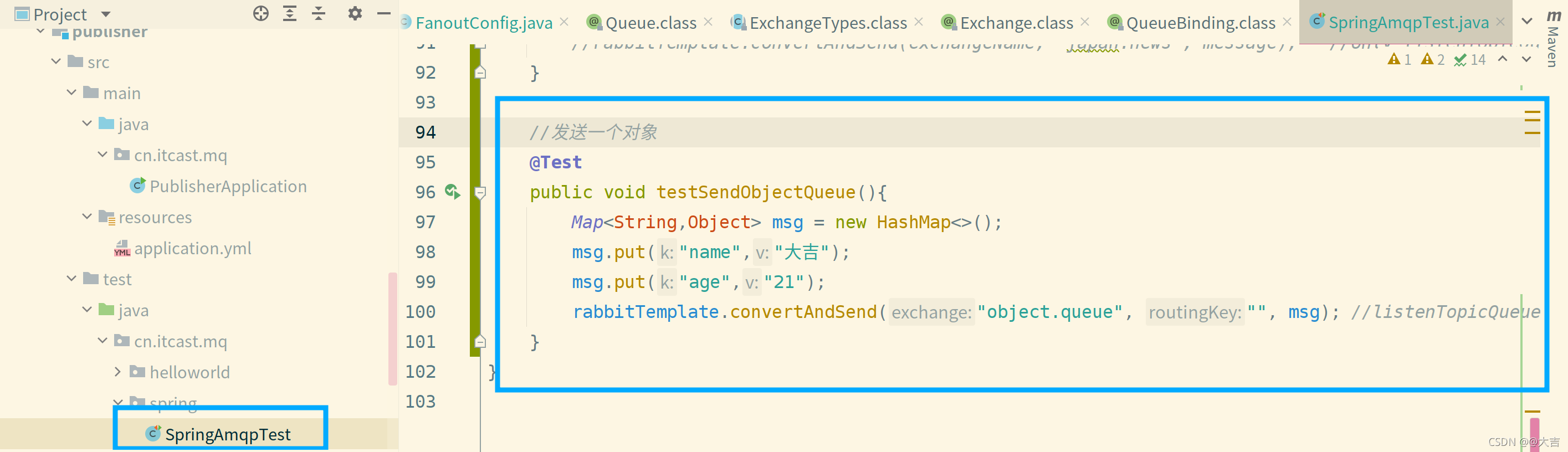
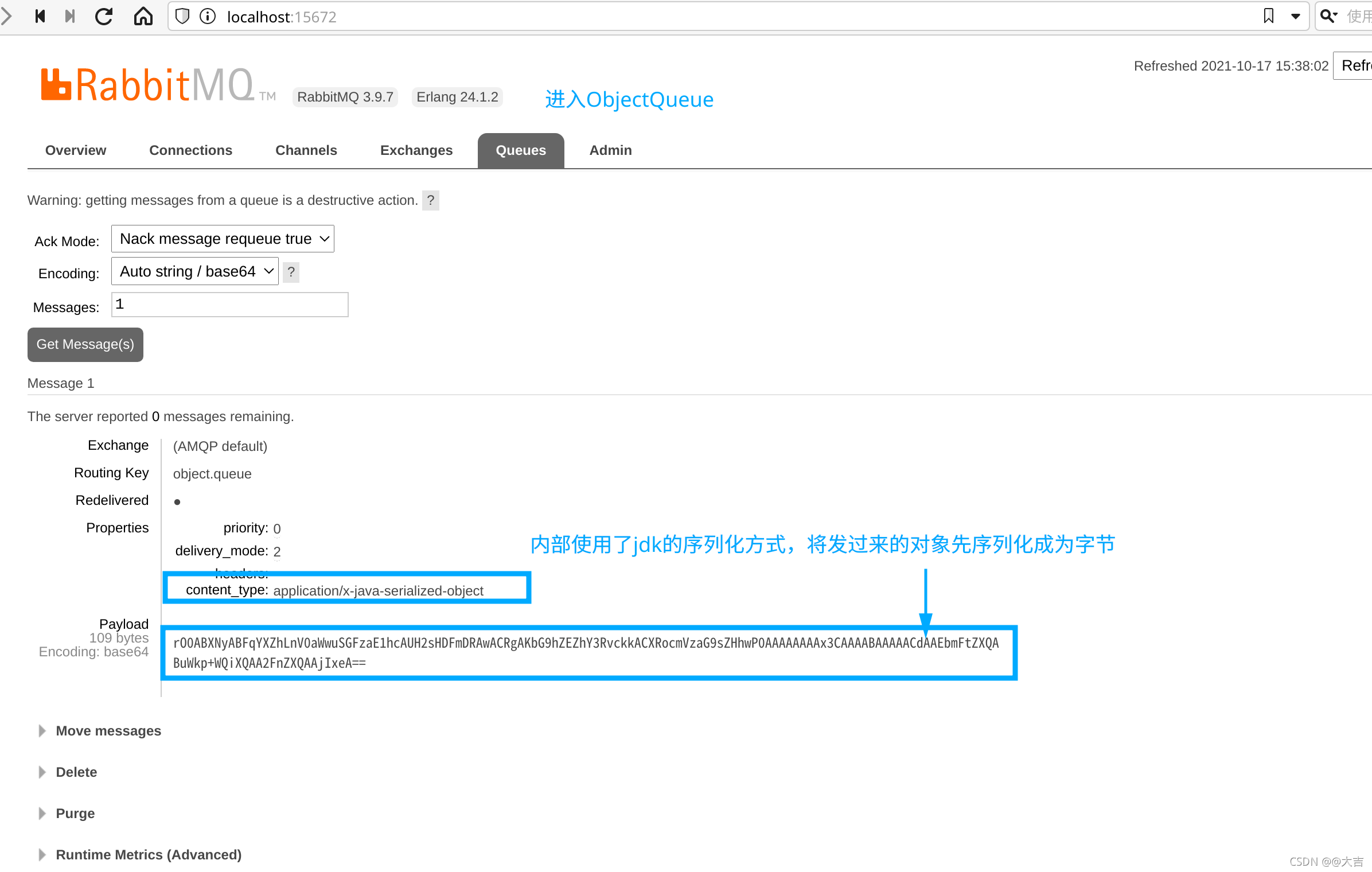
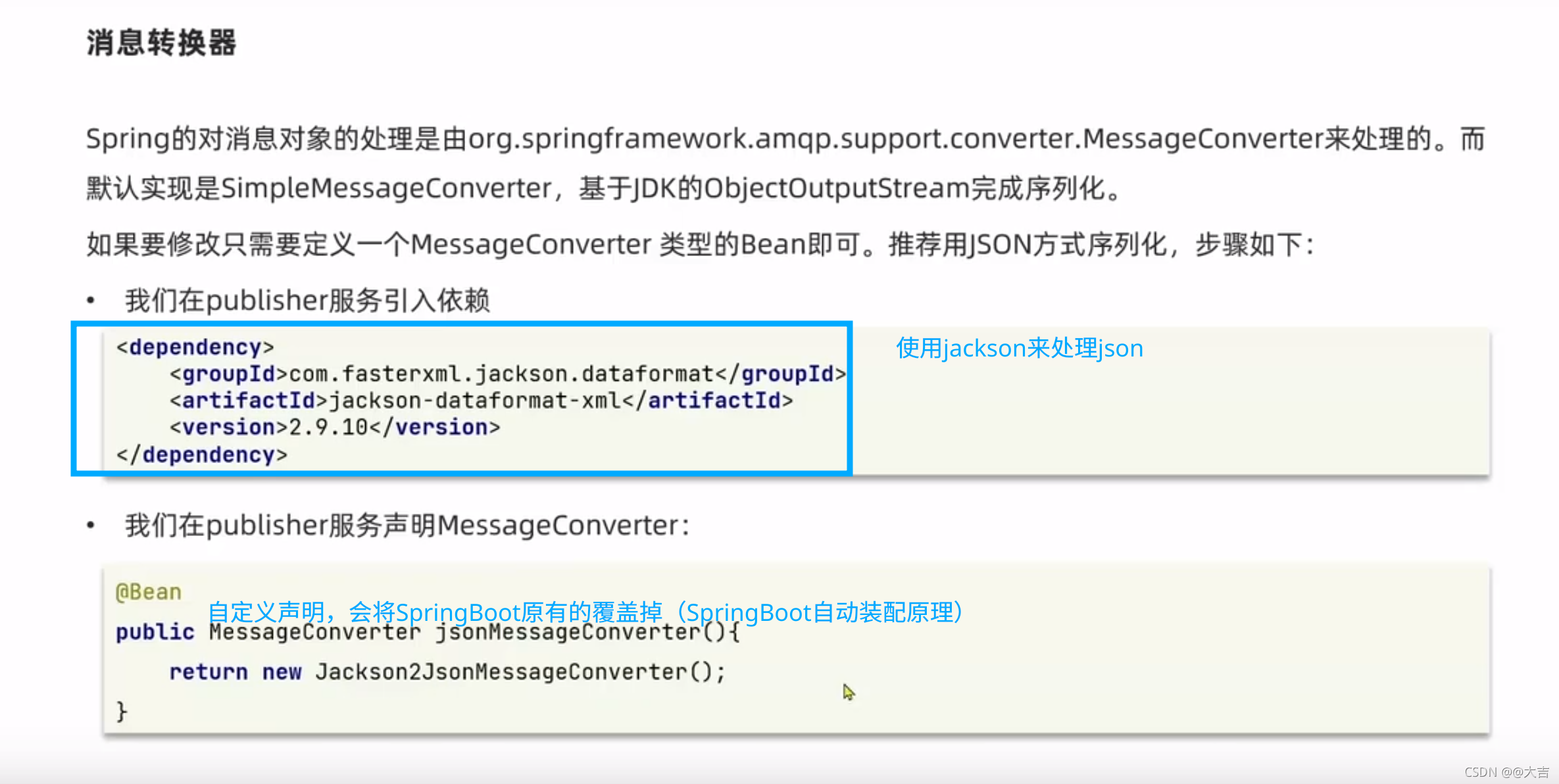
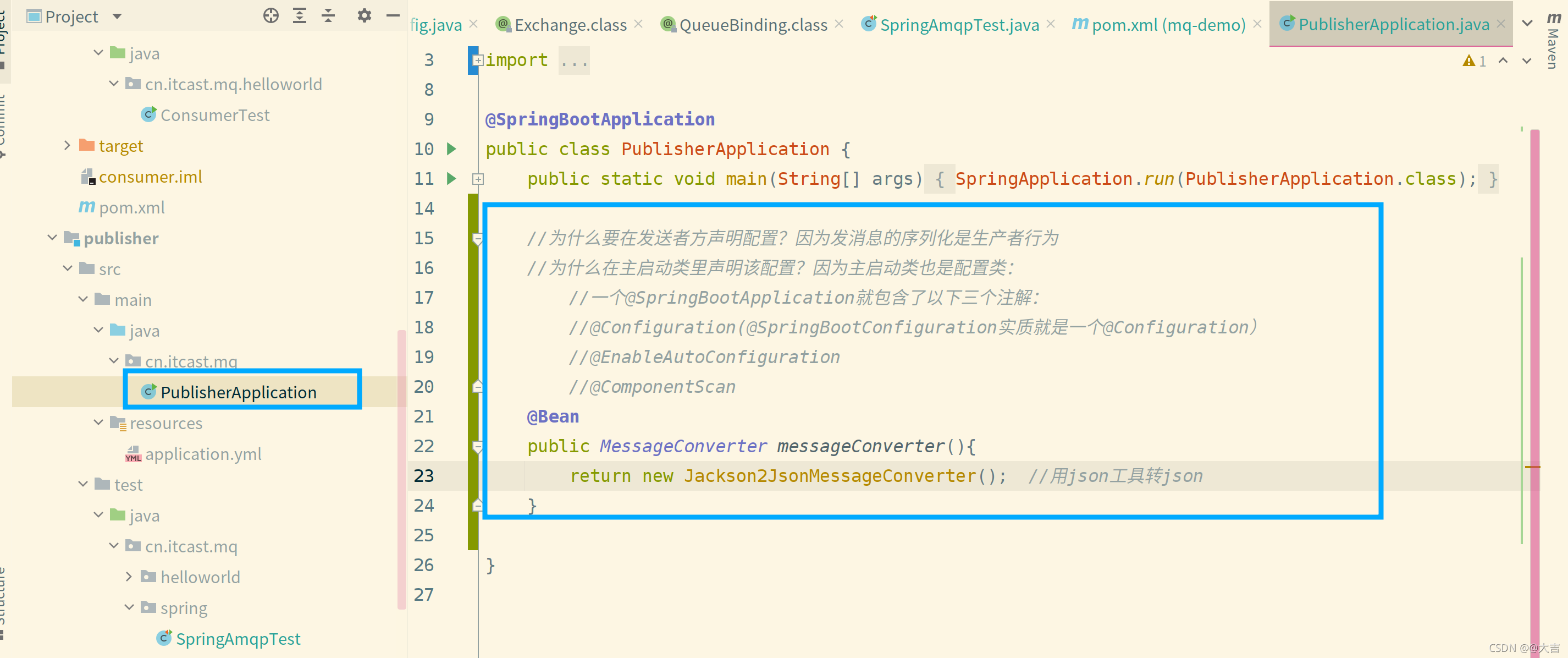
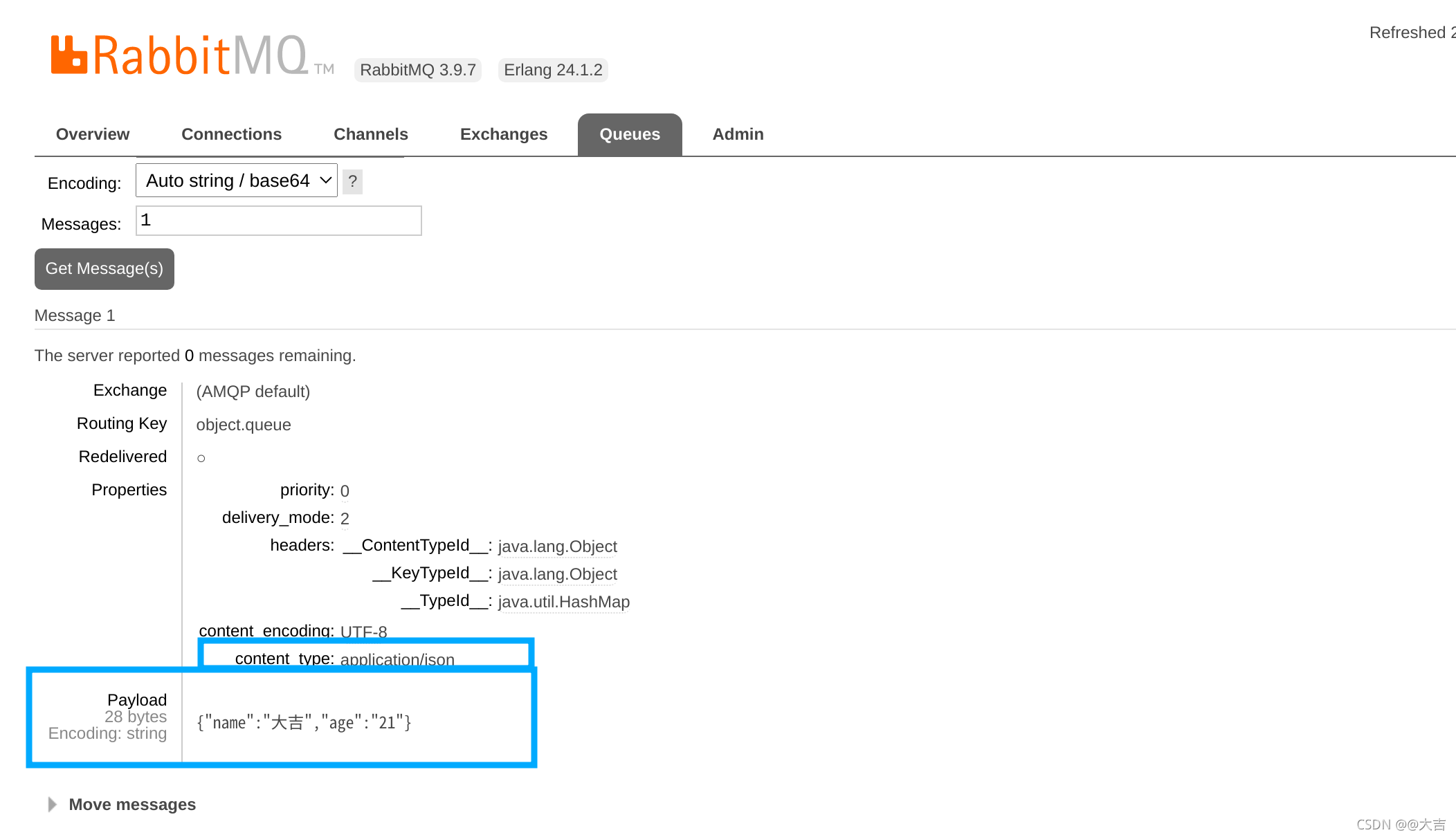
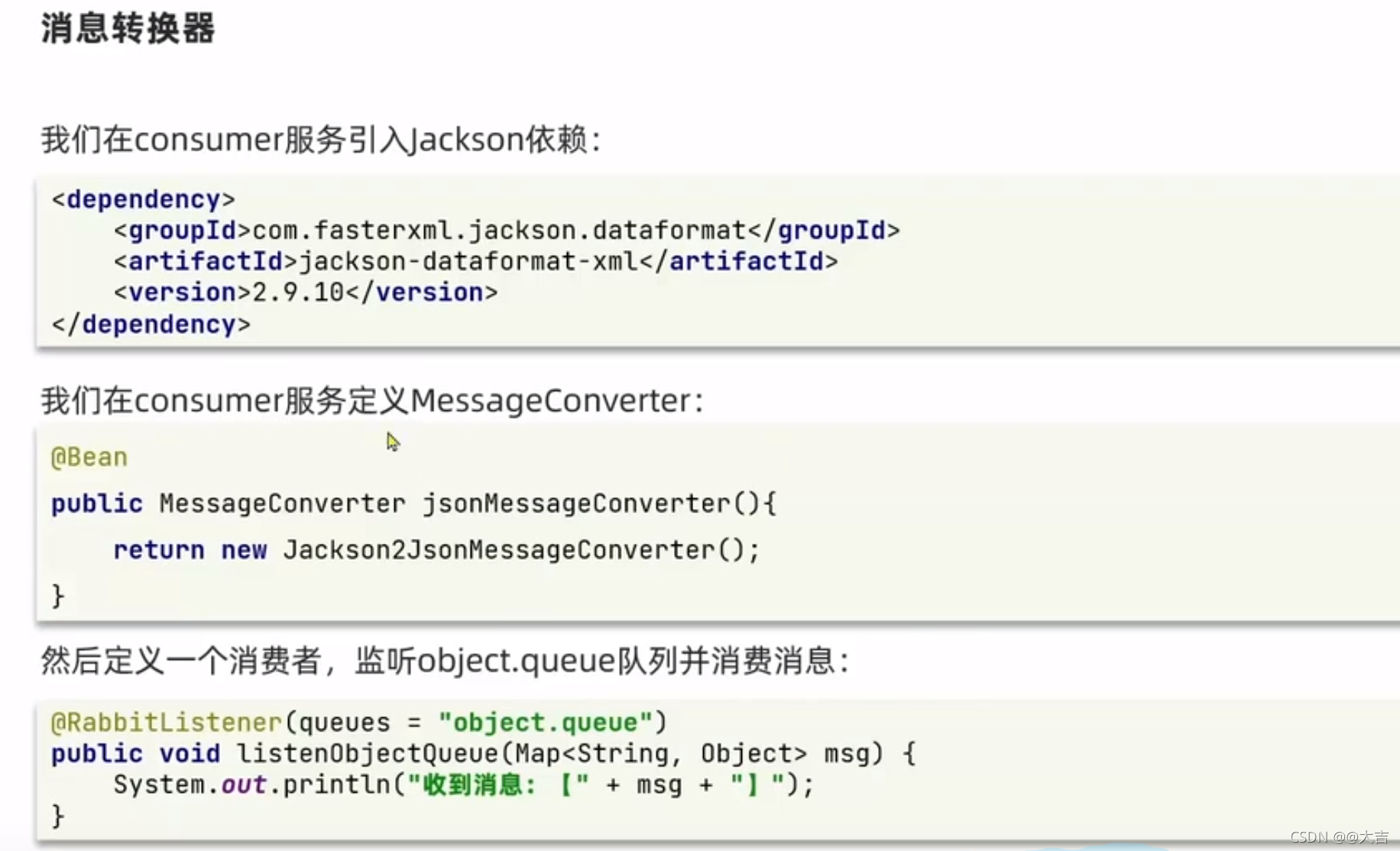

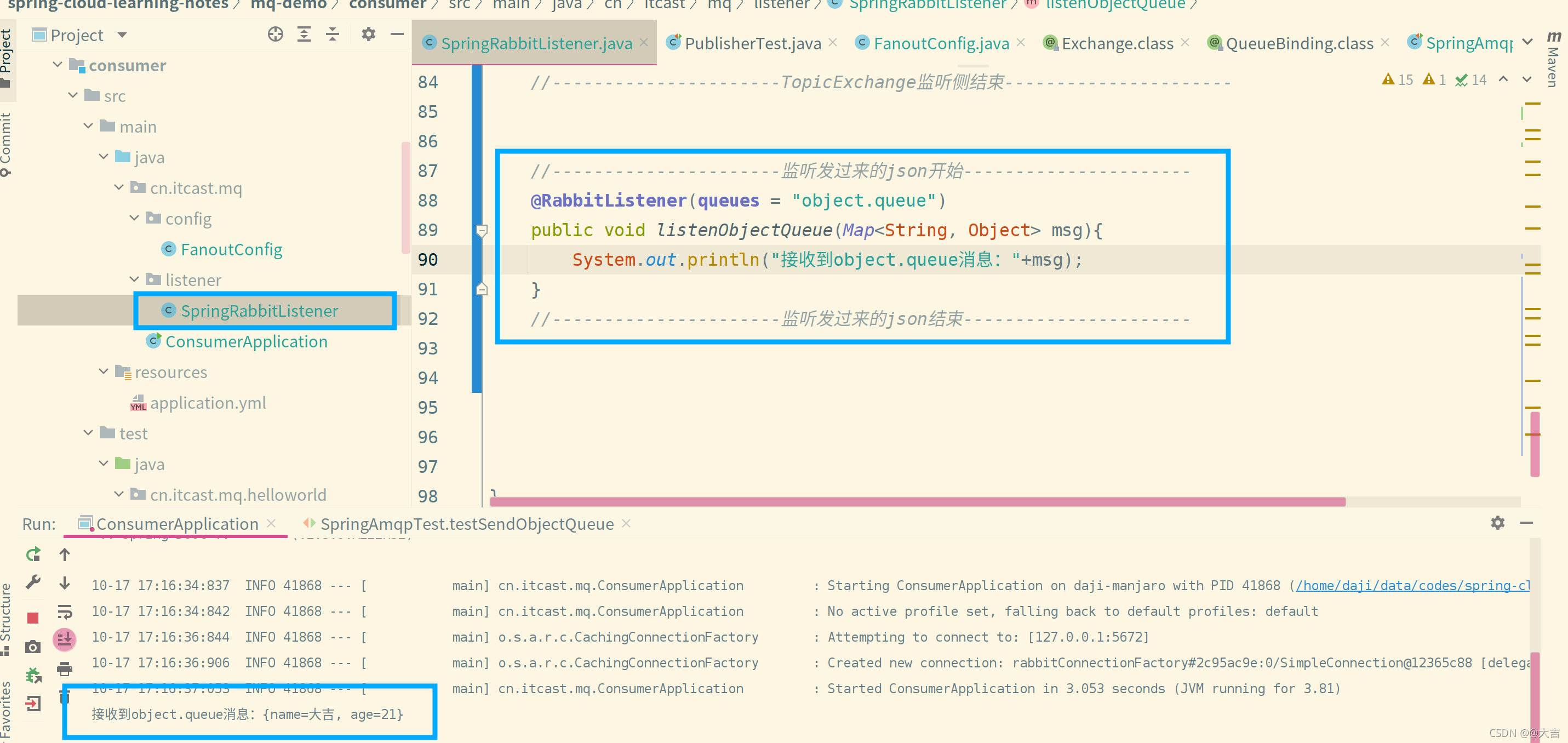
\讲义\assets\image-20210720194008781.png)
\讲义\assets\image-20210720194230265.png)
\讲义\assets\image-20210720195531539.png)
\讲义\assets\image-20210720200457207.png)
\讲义\assets\image-20210720201115192.png)
\讲义\assets\image-20210720202707797.png)
\讲义\assets\image-20210720203022172.png)
\讲义\assets\image-20210720203534945.png)
\讲义\assets\image-20210720211019329.png)
\讲义\assets\image-20210720212357390.png)
\讲义\assets\image-20210720212123420.png)
\讲义\assets\image-20210720212933362.png)
\讲义\assets\image-20210720213345003.png)
\讲义\assets\image-20210720213634918.png)
\讲义\assets\image-20210720214555863.png)
\讲义\assets\image-20210720220400297.png)
\讲义\assets\image-20210720220503411.png)
\讲义\assets\image-20210720220647541.png)
\讲义\assets\image-20210720222110126.png)
\讲义\assets\image-20210720222221516.png)
\讲义\assets\image-20210720223049408.png)
\讲义\assets\image-20210720230027240.png)
\讲义\assets\image-20210720230811674.png)
\讲义\assets\image-20210720231040875.png)
\讲义\assets\image-20210720232105943.png)
\讲义\assets\image-20210720232431383.png)







































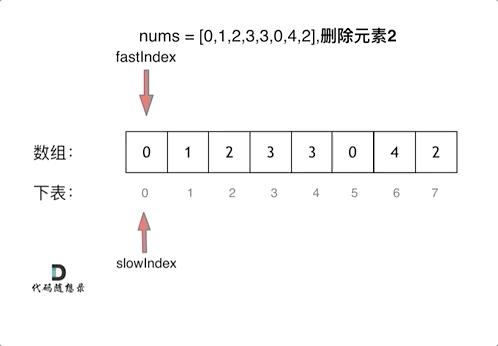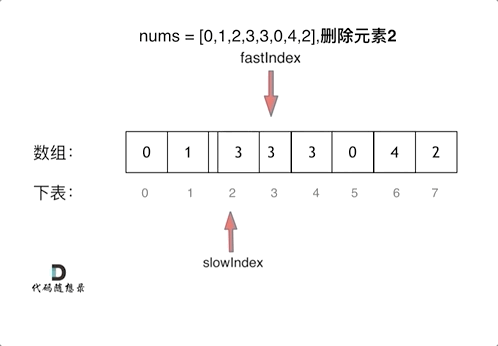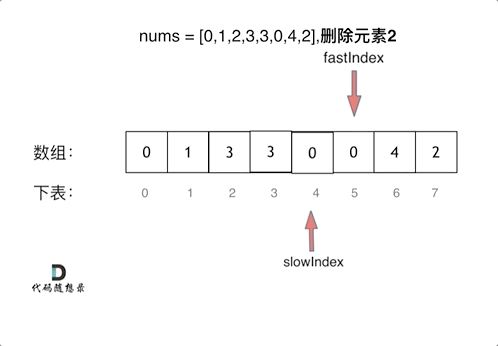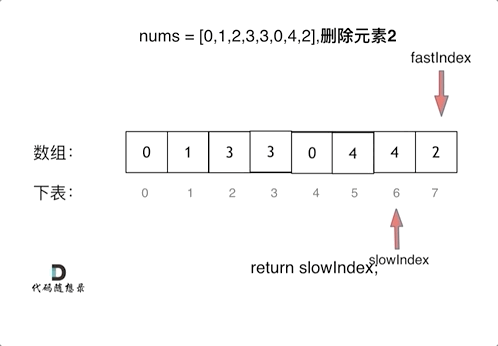










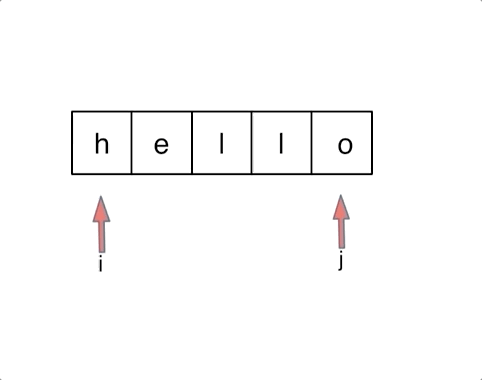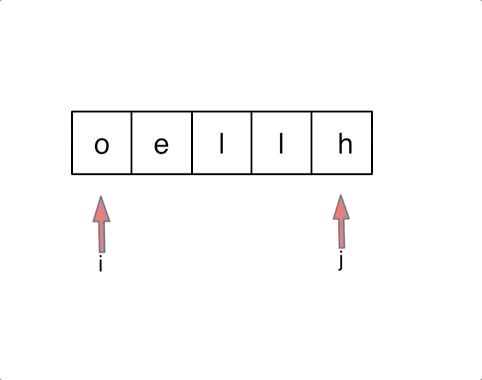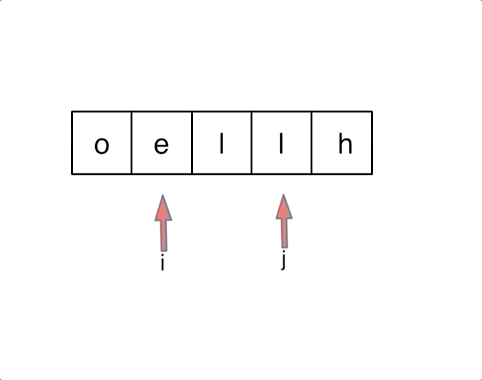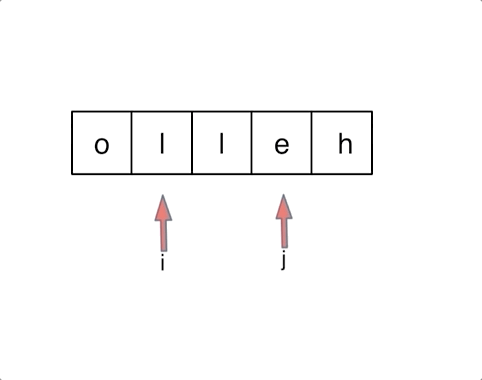
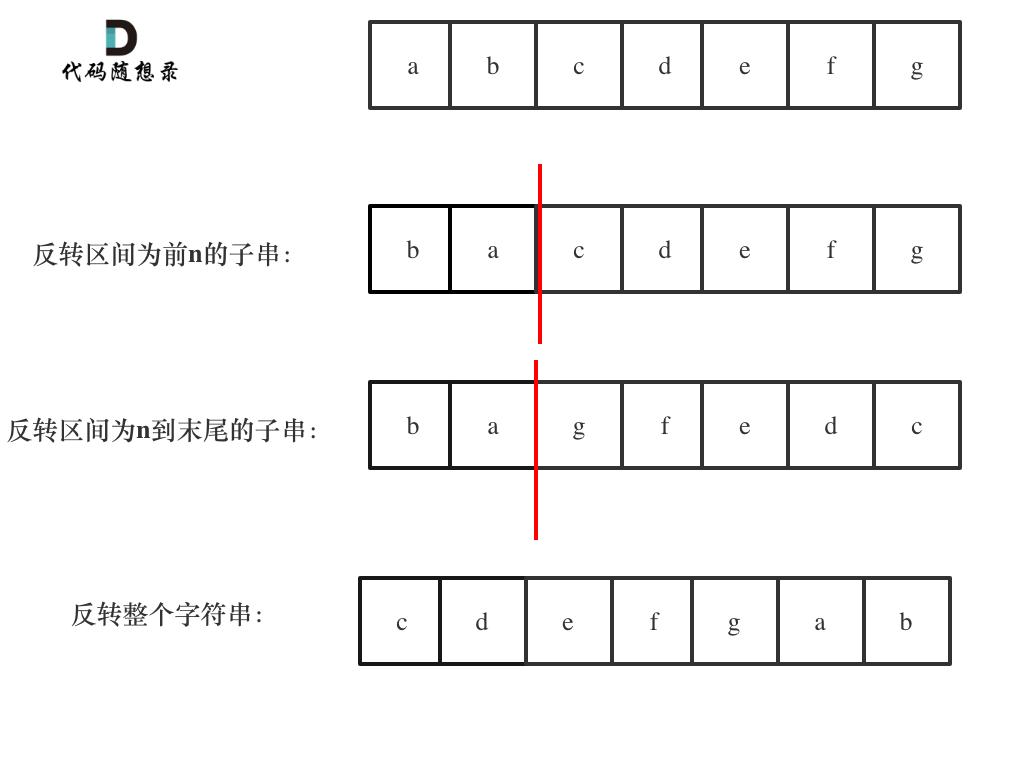


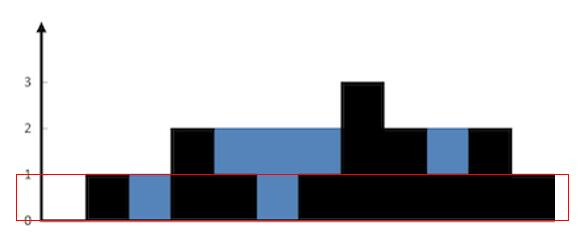
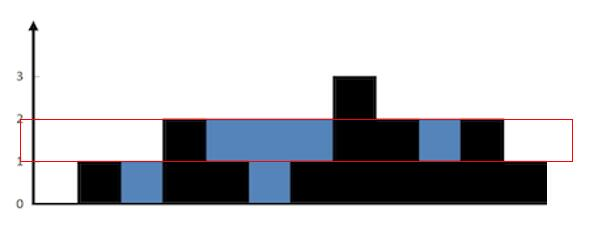
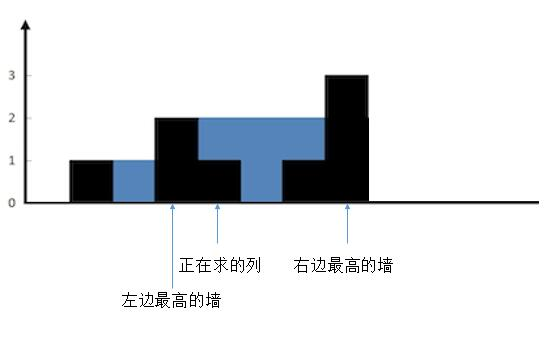



.png)
.png)